Learn how little privacy you have and how differential privacy aims to help.
“Arguing that you don’t care about the right to privacy because you have nothing to hide is no different than saying you don’t care about free speech because you have nothing to say.” ― Edward Snowden
In November 2017, the running app Strava released a data visualization map showing every activity ever uploaded to their system. This amounted to over 3 trillion GPS points, which came from devices ranging from smartphones to fitness trackers such as Fitbits and smartwatches. One of the aspects of the app is that you can see popular routes in major cities, or find individuals in remote areas with unusual exercise patterns
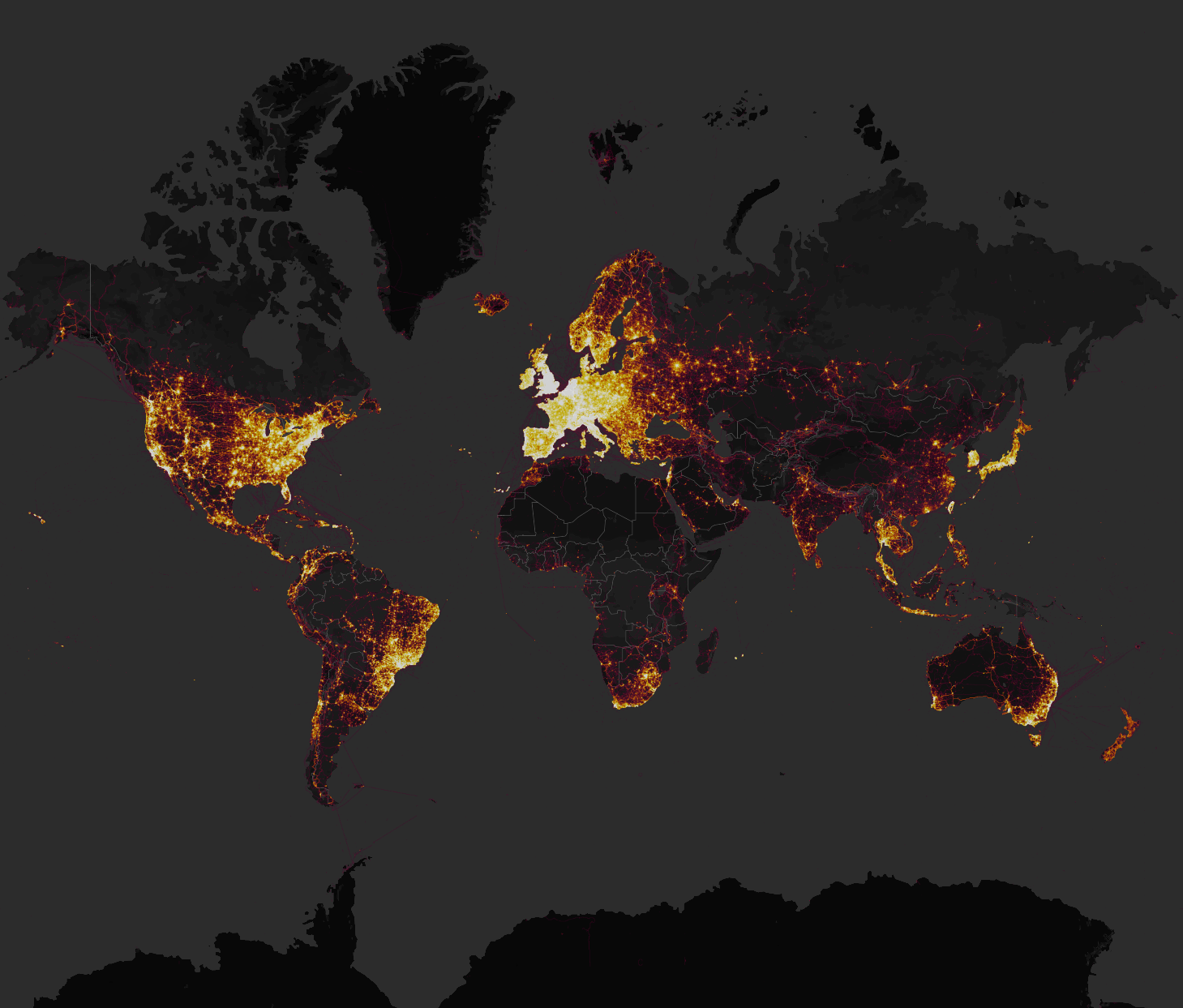
The Strava global heatmap released in November 2017. Source
The idea of sharing your exercise activities with others may seem fairly innocuous, but this map exposed the location of military bases and personnel on active service. One such location was a secret (not anymore) military base in the Helmand province of Afghanistan.
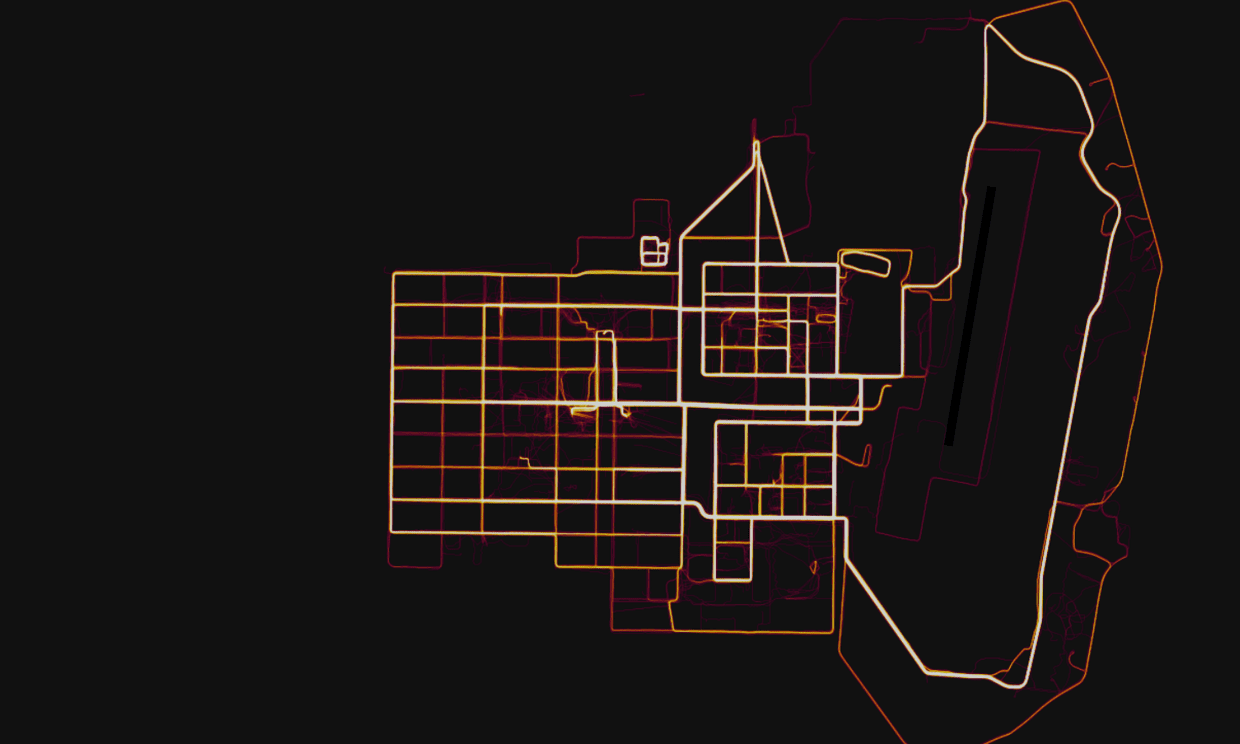
A military base in Helmand Province, Afghanistan with route taken by joggers highlighted by Strava. Photograph: Strava Heatmap
This was not the only base exposed, and in fact, activity in locations such as Syria and Djibouti, users were almost exclusively U.S. military personnel. The Strava data visualization was thus to some extent a highly detailed map of U.S. military personnel stationed worldwide.
In this age of ever-increasing data, it is becoming increasingly difficult to maintain any semblance of privacy. In exchange for convenience in our lives, we now provide constant information to companies to help improve them to improve their business operations.
Whilst this has many positive benefits, such as an IPhone knowing my location and being able to tell me about nearby restaurants or the quickest route to a location, it can also be used in adverse ways which can result in substantial privacy violations to the individual. This problem will only escalate as we move towards an increasingly data-driven society.
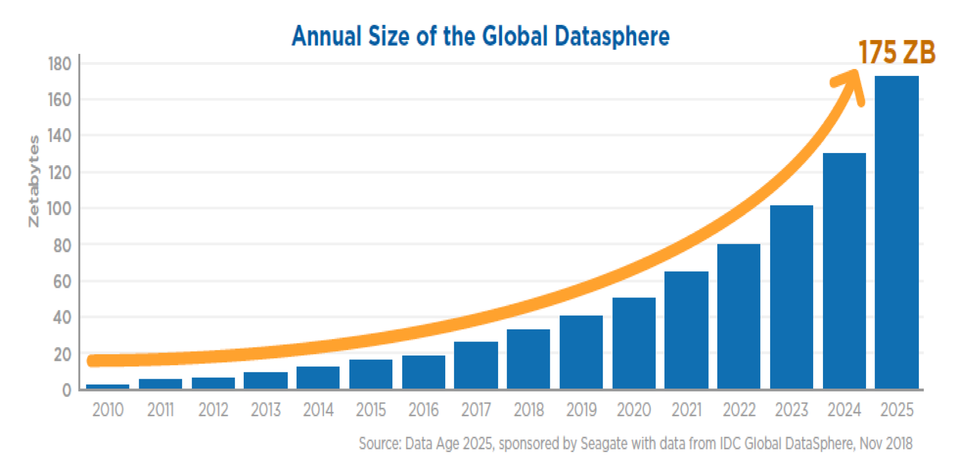
Image courtesy of Forbes.
In this article, I will talk about some of the biggest blunders in terms of privacy leaks from publicly released datasets, the different types of attacks that can be made on these datasets to re-identify individuals, as well as introduce the current best defense we have for maintaining our privacy in a data-driven society: differential privacy.
What is Data Privacy?
In 1977, Tore Dalenius articulated a desideratum for statistical databases:
Nothing about an individual should be learnable from the database that cannot be learned without access to the database. — Tore Dalenius
This idea hoped to extend the well-known concept of semantic security — the idea that when a message is encoded into ciphertext using a cryptographic algorithm, the ciphertext contains no information about the underlying message, often referred to as plaintext — to databases.
However, for various reasons, it has been proven in a paper by Cynthia Dwork, professor of Computer Science at Harvard University, that this idea put forth by Dalenius is a mathematical impossibility.
One of the reasons behind this is that whilst in cryptography we often talk about two users communicating on a secure channel whilst protected from bad actors, in the case of databases, it is the users themselves who must be considered the bad actors.
So, we don’t have very many options. One thing we can do is identify aspects of our dataset that are particularly important in identifying a person and deal with these in such a way that the dataset effectively becomes “anonymized”.
Anonymization/de-identification of a dataset essentially means that it not possible (at least ostensibly) that any given individual in the dataset can be identified. We use the term reidentification to refer to an individual who has been identified from an anonymized dataset.
The Pyramid of Identifiability
Personal data exists on a spectrum of identifiability. Think of a pyramid, where at the top of the pyramid we have data that can directly identify an individual: a name, phone number, or social security number.
These forms of data are collectively referred to as ‘direct identifiers.’
Below the direct identifiers on the pyramid is data that can be indirectly, yet unambiguously, linked to an individual. Only a small amount of data is needed to uniquely identify an individual, such as gender, date of birth, and zip code — which in combination can uniquely identify 87% of the U.S. population.
These data are collectively called ‘indirect identifiers’ or ‘quasi-identifiers.’
Below the quasi-identifiers is data that can be ambiguously connected to multiple people — physical measurements, restaurant preferences, or an individuals’ favorite movies.
The fourth stage of our pyramid is data that cannot be linked to any specific person — aggregated census data, or broad survey results.
Lastly, at the bottom of the pyramid, there is data that is not directly related to individuals at all: weather reports and geographic data.
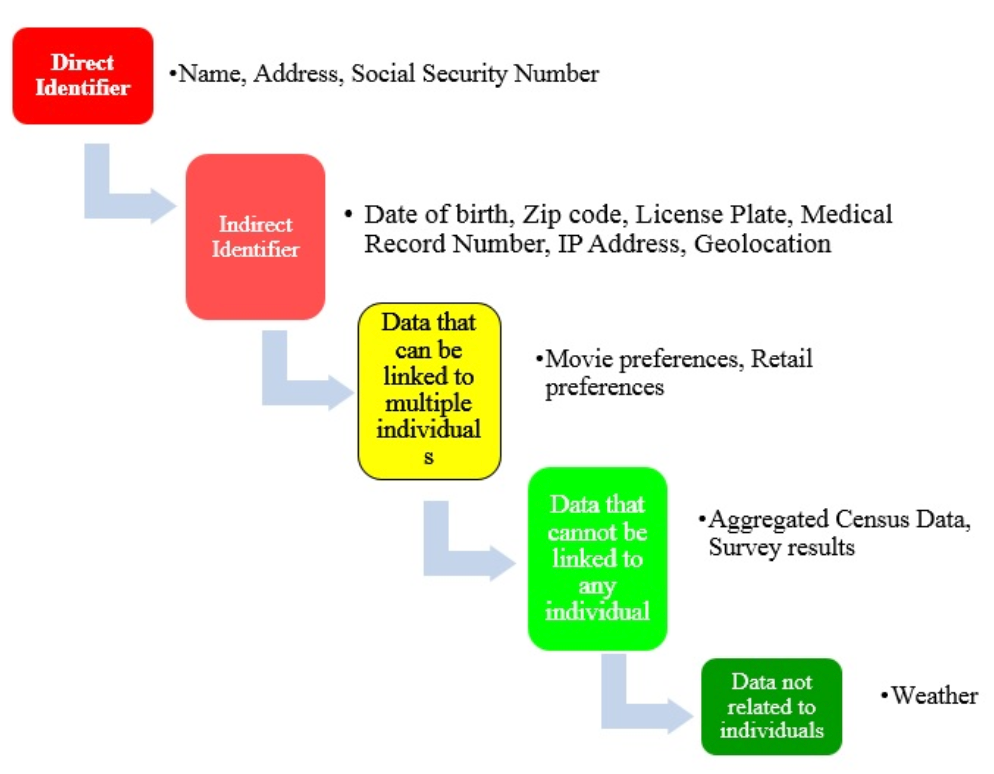
The levels of identifiability of data. Source
In this way, information that is more difficult to relate to an individual is placed lower on the pyramid of identifiability. However, as data becomes more and more scrubbed of personal information, its usefulness for research and analytics directly decreases. As a result, privacy and utility are on opposite ends of this spectrum — maximum usefulness from the data at the top of the staircase and maximum privacy at the bottom of the staircase. As data gets more and more scrubbed — its usefulness for analysis decreases.
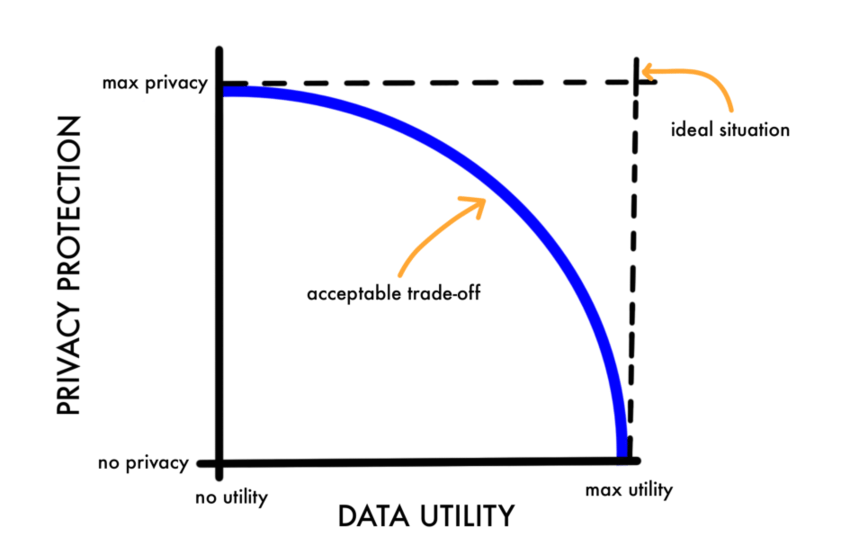
The trade-off between utility and privacy. Source
As a data scientist, this seems to be an unsatisfying answer. We would always like our data to be as accurate as possible in order that we might make the most accurate inferences. However, from the other viewpoint, the less we can discern about an individual, the better it is in terms of their privacy.
So how do we balance this trade-off? Are we doomed to either lose our accuracy or our privacy? Are we playing a zero-sum game? We will come to find that the answer is, actually, yes. However, there are now ways of mathematically determining the privacy level of a dataset such that we obtain the maximal amount of information whilst providing a suitable level of privacy for individuals present in the data. More on this later.
Scrubbing Techniques for Anonymizing Data
There are four common techniques that can be used for deidentifying a dataset:
[1] Deletion or Redaction
This technique is most commonly used for direct identifiers that you do not want to release, such as phone numbers, social security numbers, or home addresses. This can often be done automatically as it directly corresponds with primary keys in a database. Deletion simply put would mean if we had an Excel spreadsheet we would delete columns corresponding to direct identifiers.
In the table below, the first column, “Name,” can be removed without compromising the usefulness of the data for future research.
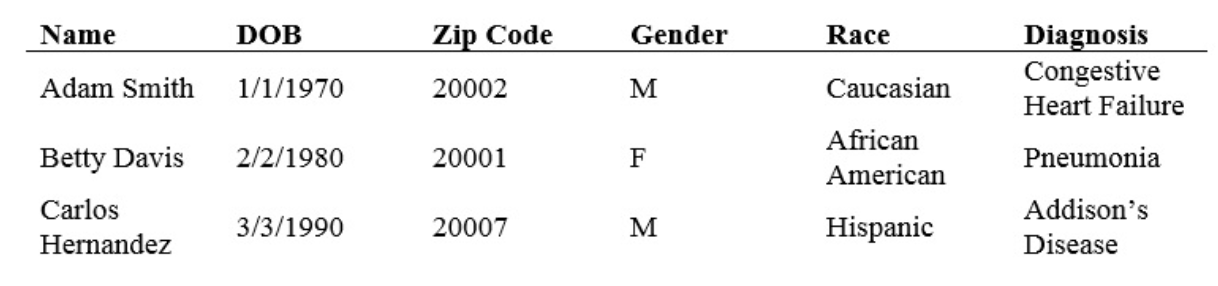
This technique is not foolproof. Direct identifiers are often not clearly marked, and important information may be mistaken for personal information and deleted accidentally.
[2] Pseudonymization
The second approach entails merely changing the ‘Name’ category to a unique but anonymous value, such as the hashed value of a column, or a user ID. These can be randomly generated or determine through an algorithm. However, this should be done with caution. If you have a list of students and you release their grades using an anonymous ID, it is probably a good idea not to do it in alphabetical order as it makes it fairly easy to reidentify people!
Similarly, if a deterministic algorithm is used to perform the pseudonymization, and the nature of the algorithm used is uncovered, it then compromises the anonymity of the individuals.
For example, in 2014 the New York City Taxi and Limousine Commission released a dataset of all taxi trips taken in New York City that year. Before releasing the data the Taxi and Limousine Commission attempted to scrub it of identifying information, specifically they pseudonymized the taxicab medallion numbers and driver’s license numbers. Bloggers were, however, able to discover the algorithm used to alter the medallion numbers and then reverse the pseudonymization.
This approach also shares the same weaknesses as the first approach — direct identifiers can be difficult to identify and replace, and indirect identifiers are inadvertently left in the dataset.
Pseudonyms also cease to be effective if the same unique pseudonym is continually used throughout a dataset, in multiple datasets, or for a long period.
[3] Statistical Noise
Whilst the first two approaches apply almost exclusively to direct identifiers, the latter two apply almost exclusively to indirect identifiers.
We can envisage the third approach of adding statistical noise as pixelating someone’s face in an image. We essentially allow the data to still exist there, but it is somewhat obscured by random noise. Depending on the way this is done, this can be a very effective technique.
Some ways statistical noise is introduced into datasets include:
- Generalization: Specific values can be reported as a range. For instance, a patient’s age can be reported as 70–80 instead of giving a full birthdate.
- Perturbation: Specific values can be randomly adjusted for all patients in a dataset. For example, systematically adding or subtracting the same number of days from when a patient was admitted for care, or adding noise from a normal distribution.
- Swapping: Data can be exchanged between individual records within a dataset.
As you may have suspected, the more direct or indirect identifiers that are removed and/or obscured with statistical noise, the lower the accuracy of our data becomes.
[4] Aggregation
The fourth technique is similar to the idea of generalization discussed in the statistical noise section. Instead of releasing raw data, the dataset is aggregated and only a summary statistic or subset is released.
For example, a dataset might only provide the total number of patients treated, rather than each patient’s individual record. However, if only a small subsample is released, the probability of reidentification increases — such as a subset that only contains a single individual.
In an aggregated dataset, an individual’s direct or indirect identifiers are withheld from publication. However, the summary data must be based on a broad enough range of data to not lead to the identification of a specific individual. For instance, in the above example, only one female patient visited the hospital. She would be easier to re-identify than if the data included thirty women who had spent time at the hospital.
Privacy Leaks
There are so many privacy leaks that I could bring up that it is actually very concerning, so I have only cherry-picked a few of these stories to illustrate certain important points.
It is important to note that I am not talking about data leaks here: where some bad actor hacks into a company or government database and steals confidential information about customers, although this is also incredibly common and becoming an increasing concern with the advent of the Internet of Things (IoT).
We are talking explicitly about data that is publicly available— i.e. you could (at least at the time) go and download it — or business data that was then used to identify individuals. This also extends to business intelligence used to reveal personal information about a person.
Netflix Prize

The $1 million Netflix Prize was a competition started by Netflix to improve the company’s movie recommendation system. For the competition, the company released a large anonymized database which contenders were to use as input data for the recommendation engine.
Two individuals, graduate student Arvind Narayanan and Professor Vitaly Shmatikov from the University of Austin were able to reidentify two individuals in the dataset published by Netflix.
“Releasing the data and just removing the names does nothing for privacy… if you know their name and a few records, then you can identify that person in the other (private) database.” — Vitaly Shmatikov
Netflix did not include names in their dataset, and instead used an anonymous identifier for each user. It was found that when the collection of movie ratings was combined with a public database of ratings, it was enough to identify the people.
Narayanan and Shmatikov demonstrated the danger by using public reviews published by a “few dozen” people in the Internet Movie Database (IMDb) to identify movie ratings of two of the users in Netflix’s data in a paper they published soon after Netflix released the data.
Exposing movie ratings that the reviewer thought were private could expose significant details about the person. For example, the researchers found that one of the people had strong — ostensibly private — opinions about some liberal and gay-themed films and also had ratings for some religious films.
More generally, the research demonstrated that information that a person believes to be benign could be used to identify them in other private databases. In privacy and intelligence circles, the result has been understood for decades, but this case brought the subject to light to the mass media.
America Online
In August 2006, AOL Research released a file containing 20 million search keywords from over 658,000 users over a 3-month period. The dataset was intended for research purposes but was removed after 3 days after gaining significant notoriety. However, it was too late at this point as the data had already been mirrored and distributed on the internet. The leak culminated in the resignation of CTO Dr. Abdur Chowdhury.
What went wrong? The data was thought to be anonymous but was found to reveal sensitive details of the searcher’s private lives, including social security numbers, credit card numbers, addresses, and, in one case, apparently a searcher’s intent to kill their wife.

Some miscellaneous queries extracted from the AOL dataset. Source
Whilst AOL did not specifically identify users, instead, personally identifiable information was present in many of the queries. Have you ever tried to Google yourself? That is essentially what resulted in privacy leaks here. Some people were even naive enough to type their social security numbers and addresses into the search database.
As the queries were attributed by AOL to particular user numerically identified accounts, an individual could be identified and matched to their account and search history by such information. The New York Times was able to locate an individual from the released and anonymized search records by cross referencing them with phonebook listings.
Target Teenage Pregnancy Leak
In an article released by New York Times writer Charles Duhigg in 2002, it was disclosed that one of Target’s statistician Andrew Pole was asked to develop a product prediction model to figure out if a customer was pregnant based on the purchases she made in-store.

News story by WCPO 9 about Target’s pregnancy prediction model. Source
The system would analyze buying habits and use this to discern the likelihood that a customer was pregnant, and would then mail coupons and advertisements for pregnancy-related items. This seems fairly innocuous, and even a positive thing to many people. However, one shopper that started to receive these coupons was a teenage girl whose outraged father called the store to complain about the advertisements. Target knew, but the father did not, that the teenage girl was pregnant.
The data supporting Target’s classification of “pregnant” was unrelated to the teenager’s identity. Instead, Target based its conclusion on the teenager’s purchases from a group of twenty-five products correlated with pregnant shoppers, such as unscented lotion and vitamin supplements.
Although such data standing alone might not reveal the shopper’s identity, Target’s big data prediction system derived a “creepy” and likely unwelcome inference from her shopping patterns.
This is essentially an example of a classification task in machine learning, and you would be surprised how easy it can be to use seemingly unrelated information to predict personal features such as age, gender, race, political affiliation, etc. In fact, this is essentially what was done by Cambridge Analytica during the 2016 U.S. Presidential Elections using data provided by Facebook.
Latanya Sweeney
In 1996, a Ph.D. student at MIT called Latanya Sweeney combined publicly released and anonymous medical data released by the Group Insurance Company (GIC) with public voter records (which she purchased for $20) and was able to reidentify Massachusetts governor William Weld from the dataset.
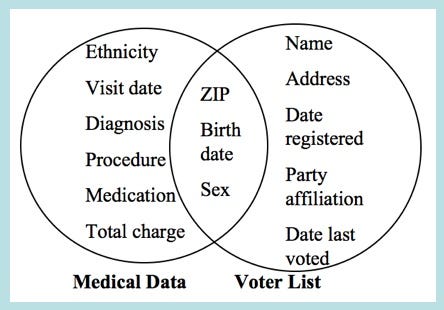
Information used by Latanya Sweeney to reidentify governor William Weld.
She then used the newly acquired information and sent a letter to his home address explaining what she had done and that the way that data had been anonymized is clearly inadequate.
The results of her reidentification experiment had a significant impact on privacy centered policymaking including the health privacy legislation HIPAA.
A full article describing the events in detail can be found here.
Since this time, she published one of the most important areas on the topic of data privacy, called “Simple Demographics Often Identify People Uniquely (Data Privacy Working Paper 3) Pittsburgh 2000”.
This paper concludes that 87% of individuals in the U.S. can be uniquely identified alone by knowing 3 pieces of information: gender, date of birth, and zip code.
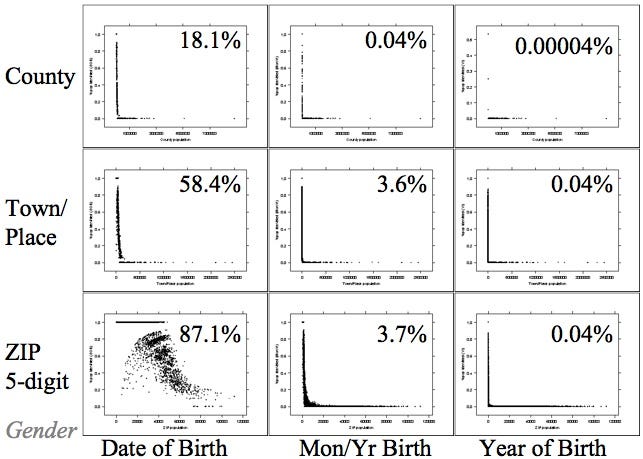
A figure from Latanya Sweeney’s paper showing the percentage of the population identifiable via different quasi-identifiers.
Latanya is now a professor and runs the Data Privacy Lab at Harvard University. Some of the techniques for anonymizing datasets are outlined later in this article, such as ‘k-anonymity’.
Golden State Killer
This story is probably the most interesting and has the most far-reaching implications. The infamous Golden State Killer, a murderer and serial rapist active in Sacramento Country, California, between 1978 and 1986, was finally caught in April 2018 at age 72 when a relative of his uploaded genetic information from a personal genomics test by 23AndMe to a public online database.
Investigators uploaded the criminal’s DNA to the database in hope that they would find a partial match. To their amazement, they did. The investigators began exploring family trees to match DNA collected from one of the crime scenes. From there, they investigated individuals within those trees in order to narrow down a suspect.
Eventually, they found an individual within the right age group that had lived in the areas that the Golden State Killer had been active. They gathered the DNA of James DeAngelo from items he had thrown away, which were then analyzed in a lab and found to be a direct match to the killer.
Whilst catching a serial killer is clearly a positive thing, this use of genetic information raised significant ethical questions about how genetic information should be used:
[1] The most obvious of these is that your genetic information directly identifies you — you cannot use mathematical techniques to ‘anonymize’ it, and if you did, it would no longer be representative of you in any way.
[2] The second and perhaps more haunting idea is that a fairly distant relative of yours has the capability of violating your own privacy. If your cousin is found to have a genetic predisposition to ovarian cancer and the information is in an online database, that can directly be linked to you by an insurance company to raise your premium. This destroys the whole concept of informed consent which is present during most data collection processes.
In 2008 the Genetic Information Non-Disclosure Act (GINA) was introduced in the U.S. that prohibited certain types of genetic discrimination. This act meant that health insurance providers could not discriminate on the basis of genetics.
For example, if it was found that an individual had a mutated BRCA2 gene — a gene that is commonly associated with an increased risk of contracting breast cancer — they would be forbidden to use this information to discriminate against the individual in any way.
However, this act said nothing about discrimination in life insurance policies, disability insurance policies, or long-term health care policies. If you uploaded a personal genomics test to an online and public database, you better believe that your life insurance company knows about it.
Reidentification Attacks
In the previous section, we saw that even anonymized datasets can be subject to reidentification attacks. This can cause harm to the individuals in the dataset, as well as those associated with analyzing or producing the dataset.
Of the leaks discussed, several of these occurred in public datasets that were released for research purposes or as part of a company’s commercial activities.
This presents significant issues for both companies and academia. The only two real options are:
(1) to not use or severely restrict public data, which is a non-starter in a global society and would significantly stifle scientific progress, or
(2) develop viable privacy methods to allow public data to be used without substantial privacy risks to individual participants that are part of the public data.
However, if we are going to develop privacy methods, we need to be aware of what types of attacks individuals might be able to perform on a database.
Linkage Attack
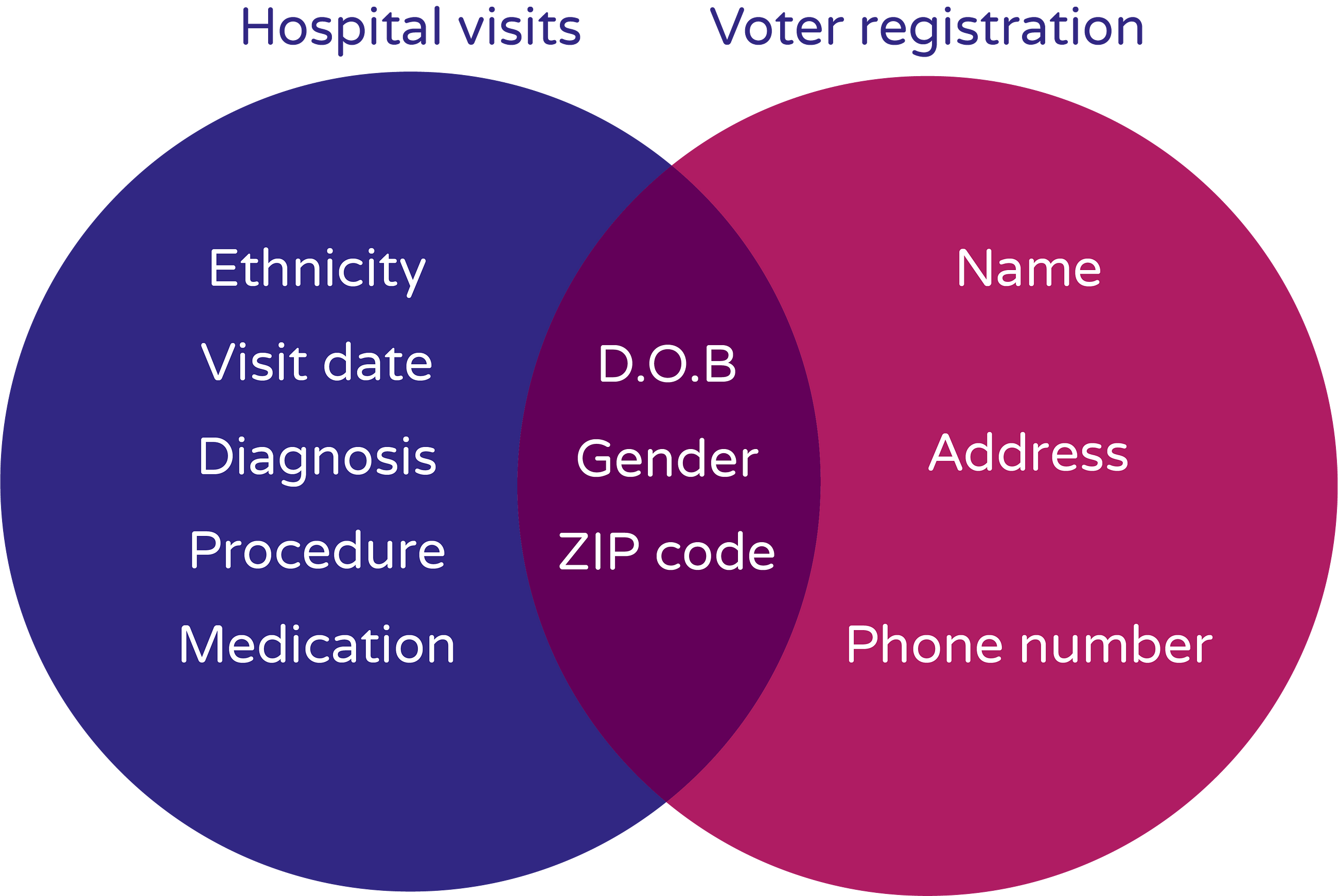
A linkage attack attempts to re-identify individuals in an anonymized dataset by combining that data with background information. The ‘linking’ uses quasi-identifiers, such as zip or postcode, gender, salary, etc that are present in both sets to establish identifying connections.
Many organizations aren’t aware of the linkage risk involving quasi-identifiers, and while they may mask direct identifiers, they often don’t think of masking or generalizing the quasi-identifiers. This is exactly how Latanya Sweeney was able to find the address of governor William Weld and is also what got Netflix in trouble during their Netflix Prize competition!
Differencing Attack
This is an attack where an attacker can isolate an individual value by combining multiple aggregate statistics about a data set. This essentially attacks the aggregation method that was discussed in the data scrubbing methods section.
A simple example of this would be querying a database about users who have cancer. We ask the database about users who have cancer, and we then ask the database about users who have cancer whose name is not John. We can potentially use these combined query results to perform a differencing attack on John.
Here is another example, consider a fictional Loyalty Card data product where the data product contains the total amount spent by all customers on a given day and the total amount spent by the subgroup of customers using a loyalty card. If there is exactly one customer who makes a purchase without a loyalty card, some simple arithmetic on the two statistics for that day reveals this customer’s precise total amount spent, with only the release of aggregate values.
A more general version of this attack is known as a composition attack. This attack involves combining the results of many queries to perform a differencing attack.
For example, imagine a database that uses statistical noise to perturb its results. If we ask the database the same query 10,000 times, depending on the way it creates statistical noise, we may be able to average out the statistical noise data and obtain a result close to the true value. One way of tackling this might be to limit the number of queries allowed or add the same noise to queries that are the same, but doing this adds additional issues to the system.
Homogeneity Attack
Example of a homogeneity attack on a de-identified database
A homogeneity attack leverages the case where all values of a sensitive data attribute are the same. The above table provides an example where the sex and zip code of a database have been retracted and generalized, but we are still able to determine a pretty good idea of the salaries of every individual in zip code 537**. Despite the fact we cannot explicitly identify individuals, we may still be able to find out that one of the entries relates to them.
Background Knowledge Attack
Background knowledge attacks are particularly difficult to defend against. They essentially rely on background knowledge of an individual which may be instrumental in deidentifying someone in a dataset.
For example, imagine an individual that knows that their neighbor goes to a specific hospital and also knows certain attributes about them such as their zip code, age, and sex, and they want to know what medical condition they may have. They have found that there are two entries in the database that correspond to this information, one of which has cancer and the other of which has heart disease. They have already narrowed down the results in the database considerably, but can they fully identify the individual?
Now imagine that the neighbor is Japanese, and the individual knows that Japanese people are much less likely to contract heart disease than a typical individual. They may conclude from this with reasonable certainty that the individual has cancer.
Background knowledge attacks are often modeled using Bayesian statistics involving prior and posterior beliefs based on attributes within the dataset since this is essentially what an individual is doing when performing this kind of attack. A condition known as Bayes-optimal privacy is known to help defend against this kind of attack.
K-Anonymity, L-Diversity, and T-Closeness
In this section, I will introduce three techniques that can be used to reduce the probability that certain attacks can be performed. The simplest of these methods is k-anonymity, followed by l-diversity, and then followed by t-closeness. Other methods have been proposed to form a sort of alphabet soup, but these are the three most commonly utilized. With each of these, the analysis that must be performed on the dataset becomes increasingly complex and undeniably has implications on the statistical validity of the dataset.
K-Anonymity
As Latanya Sweeney states in her seminal paper:
A release provides k-anonymity protection if the information for each person contained in the release cannot be distinguished from at least k-1 individuals whose information also appears in the release.
This essentially means that as long as my dataset contains at least k entries for a given set of quasi-identifiers, then it is k-anonymous. If we take the superkey of zip code, gender, and age as done previously, a dataset would be 3-anonymous if each and every possible combination of zip code, gender, and age in the dataset had at least 3 entries within them.
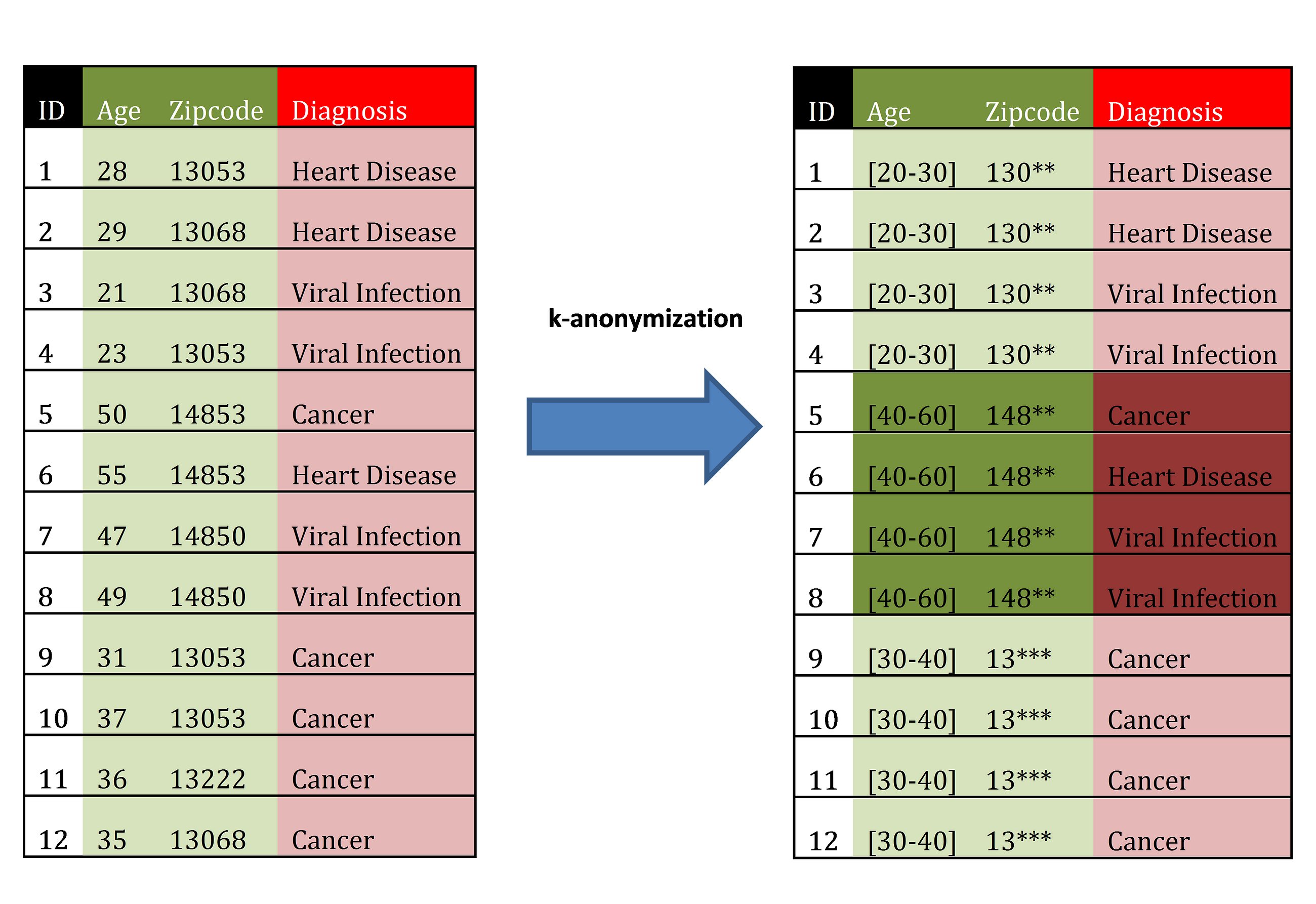
Original dataset (left) and 4-anonymous dataset (right). Source
This helps to prevent linkage attacks since an attacker can not make links to another database with a high degree of certainty. However, it is still possible for someone to perform a homogeneity attack, as in the example where all k individuals have the same value. For example, if three individuals that happen to be the same age group, gender, and zip code also all happen to have the same type of cancer, k-anonymity does not protect their privacy. Similarly, it does not defend against background knowledge attacks.
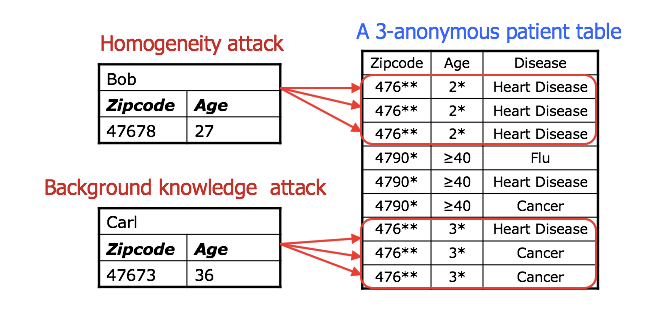
An example of homogeneity and background knowledge attacks on k-anonymous datasets. Source
What is an acceptable level of k-anonymity? There is no clear cut definition but several papers have argued that a level of k=5 or k=10 is preferred. Most individuals in the academic realm seem to agree that k=2 is insufficient and k=3 is the bare minimum needed to preserve privacy (although does not necessarily guarantee it).
As you have probably realized, the higher level of k that you choose, the lower utility our data has since we must perform generalization (reducing the number of unique values in a column), blurring (obscuring certain data features or combining them), and suppression (deletion of row tuples that cannot satisfy k=3 after other de-identification methods are applied). Instead of suppression, synthetic rows can be added that take samples from either the marginal distribution of each column or the joint distribution of all columns.
Clearly, all of these mechanisms will substantially skew or bias the statistics of a dataset, and the trade-offs of these techniques are still a subject of academic research. This is discussed for HarvardX data in the publication “Statistical Tradeoffs between Generalization and Suppression in the De-identification of Large-Scale Data Sets” by Olivia Angiuli and Jim Waldo.
Making a dataset k-anonymous can result in huge proportions of the data being lost (80% of the data can be removed via suppression alone) or added (such as adding 3 rows for every row currently in a dataset to make it 4-anonymous) when the number of quasi-identifiers becomes large, which occurs in most large public datasets.
Having tried to make a k-anonymous dataset myself before I can tell you that it is by no means easy to achieve anonymity and still have data that is not useless.
L-Diversity
Several people have noted the possibility of attacks that can be performed on k-anonymous datasets, so privacy researchers have taken it a step further and proposed l-diversity. The authors define l-diversity to be:
…the requirement that the values of the sensitive attributes are well-represented in each group.
They expand on this in mathematical detail to essentially mean that any attribute that is considered ‘sensitive’, such as what medical conditions an individual has, or whether a student passed or failed a class, takes on atleast L distinct values within each subset k.
In simpler terms, this means that if we take a block of four individual’s data from a university class that are found to have the same quasi-identifiers (such as same zip code, gender, and age), then there must be at least L distinct values within that group — we cannot have all of the individuals in the group with just a passing grade.
This helps to ensure that individuals cannot be uniquely identified from a homogeneity attack. However, it may still violate someone’s privacy if all of the values of the sensitive attribute are unfavorable — such as all having different but low grades in a ‘grade’ column, or all having different types of cancer in a ‘medical condition’ column.
This does not make things perfect but it is a step further than k-anonymity. However, once again, it raises additional questions as to the statistical validity of a dataset after this is performed on a dataset, since it will involve suppressing or adding rows which will alter the distribution of the data and also acts as a form of self-sampling bias.
For example, in EdX data, it was found that students that completed classes provided much more information about themselves than casual observers of classes, and thus most of these could be uniquely identified. Thus, when k-anonymity and l-diversity were used on the dataset, it removed most of the people who had completed the classes! Clearly, this is not an ideal circumstance, and there are still open questions about how this should be handled to minimize the introduction of bias to datasets in this manner.
T-Closeness
Yet another extension of k-anonymity and l-diversity, privacy researchers also proposed t-closeness. They describe t-closeness as:
We propose a novel privacy notion called t-closeness, which requires that the distribution of a sensitive attribute in any equivalence class is close to the distribution of the attribute in the overall table (i.e., the distance between the two distributions should be no more than a threshold t). We choose to use the Earth Mover Distance measure for our t-closeness requirement.
In the above paragraph, an equivalence class is meant as the k individuals in a k-anonymous subset. The idea is essentially to ensure that not only are the values in an equivalence class l-diverse, but that the distribution of those L distinct values should be as close to the overall data distribution as possible. This would aim to help remove some of the bias that was introduced into the EdX dataset with regards to removing people who had successfully completed courses.
Here are reference scientific papers for these and other algorithms aimed at protecting data privacy:
What Regulations Exist?
There are a number of privacy regulations that exist and they can vary substantially, it would be a bit arduous to write and explain them all, so I have just chosen as an example to compare the HIPAA and FERPA regulations in the United States.
Health Insurance Portability and Accountability Act (HIPAA)
This regulation covers all medical data in the U.S. and initially (when released in 1996) specified that all personally identifiable information (PII) must be removed from a dataset before it is released. From our discussion early, this corresponds to direct identifiers — those pieces of information that directly identify who you are, such as name, address, and phone number. Thus HIPAA could be satisfied by merely suppressing (deleting/removing) these features from the publicly released data.
Since then, the regulations have been updated that now require a dataset to be de-identified in compliance with the HIPAA Privacy Rule, which states that either:
- The removal of 18 specific identifiers listed above (Safe Harbor Method)
- The expertise of an experienced statistical expert to validate and document the statistical risk of re-identification is very small (Statistical Method)
The 18 attributes that come under the purview of protected health information are:
- Names
- All geographical identifiers smaller than a state, except for the initial three digits of a zip code if, according to the current publicly available data from the U.S. Bureau of the Census: the geographic unit formed by combining all zip codes with the same three initial digits contains more than 20,000 people.
- Dates (other than year) directly related to an individual
- Phone Numbers
- Fax numbers
- Email addresses
- Social security numbers
- Medical record numbers
- Health insurance beneficiary numbers
- Account numbers
- Certificate/license numbers
- Vehicle identifiers and serial numbers, including license plate numbers;
- Device identifiers and serial numbers;
- Web Uniform Resource Locators (URLs)
- Internet Protocol (IP) address numbers
- Biometric identifiers, including finger, retinal and voiceprints
- Full face photographic images and any comparable images
- Any other unique identifying number, characteristic, or code except the unique code assigned by the investigator to code the data
Note that HIPAA data does not explicitly have to be k-anonymous.
Family Education Rights and Privacy Act (FERPA)
This regulation covers all education data in the U.S., including K-12 and university information. This regulation specifies that not only must all PII be removed but there must also be no possibility of anyone being identified to a high degree of certainty. This means we must satisfy a more stringent requirement than HIPAA. If we are looking at university medical information, the more stringent regulation is the one that must be followed, so in this case, FERPA would be dominant instead of HIPAA.
The requirements of FERPA can be satisfied by using k-anonymity.
Differential Privacy
The whole point of this article has been to build you up to differential privacy and how it plans to revolutionize the notion of privacy in a data-driven world. Differential privacy, in various forms, has been adopted by Google, Apple, Uber, and even the US Census Bureau.
We have seen with the methods of k-anonymity, l-diversity, and t-closeness that they are by no means perfect, and they cannot guarantee that they are futureproof. We want to enable statistical analysis of datasets — such as inference about populations, machine learning training, useful descriptive statistical — whilst still protecting individual-level data against all attack strategies and auxiliary information that is available about the individual. With the previous methods, someone could come along with new technology or algorithm in 10 years time and reidentify the entire dataset — there are no formal guarantees of privacy.
This is what differential privacy offers us: a mathematical guarantee of privacy that is measurable and is futureproof. With differential privacy, the goal is to give each individual roughly the same privacy that would result from having their data removed. That is, the statistical functions run on the database should not overly depend on the data of any one individual.
Cryptography does not work with datasets, because the potential adversaries are the dataset users themselves. Thus, privacy researchers have developed a mathematical framework under the assumption that the data analyst is an adversary, and aims to minimize the possibility that sensitive information is disclosed to the analyst, even when the analyst asks multiple sequential queries to the dataset.
The revelation came when privacy researchers stopped trying to ensure that privacy was a property of the data output, and instead began to think of it as a property of the data analysis itself. This led to the formulation of differential privacy which offers a form of ‘privacy by design’, instead of tagging privacy on at the end as an afterthought.
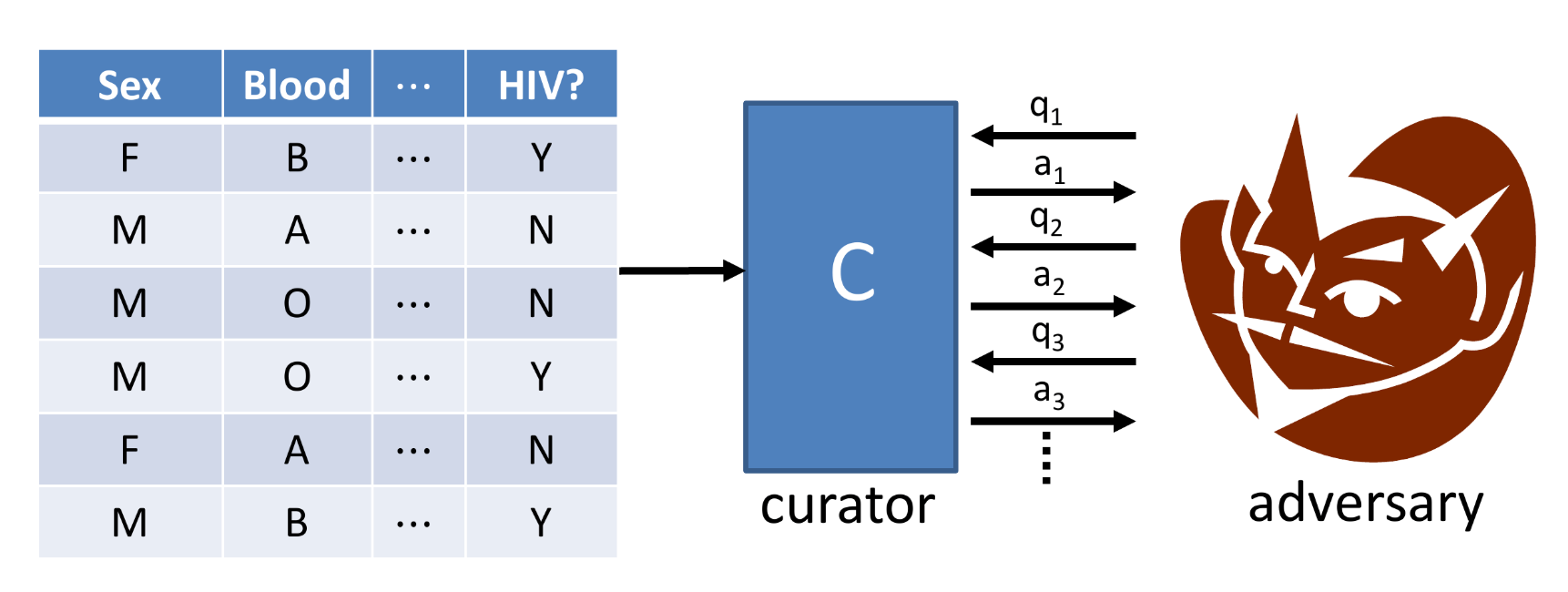
A curator that mediates the interfacing of the data analyst (adversary) with the raw data source (our database system).
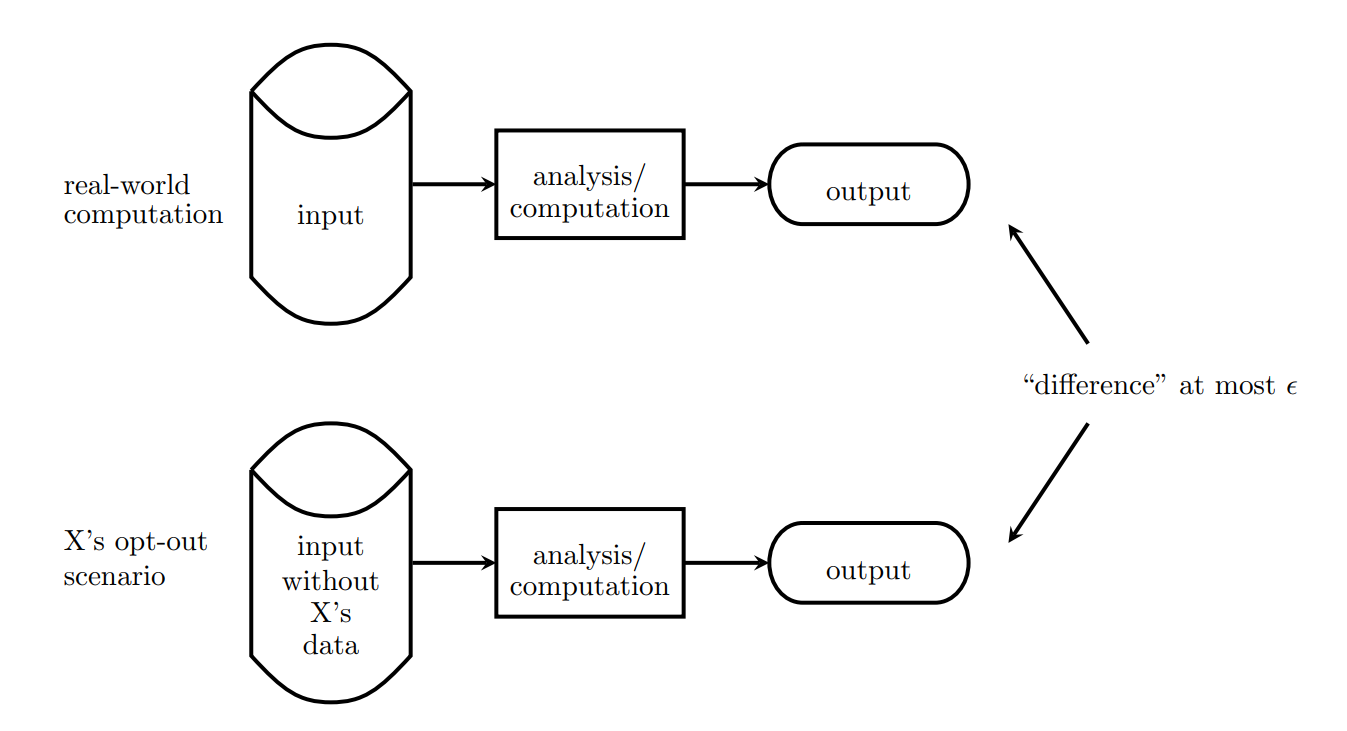
Thus our requirement is that an adversary shouldn’t be able to tell if any single individual’s data were changed arbitrarily. In simpler terms, if I remove the second entry in the dataset, the adversary would not be able to tell the difference between the two datasets.
We measure the difference between (1) the dataset with individual X, and (2) the dataset without individual X, using a variable known as ϵ.
How does this work?
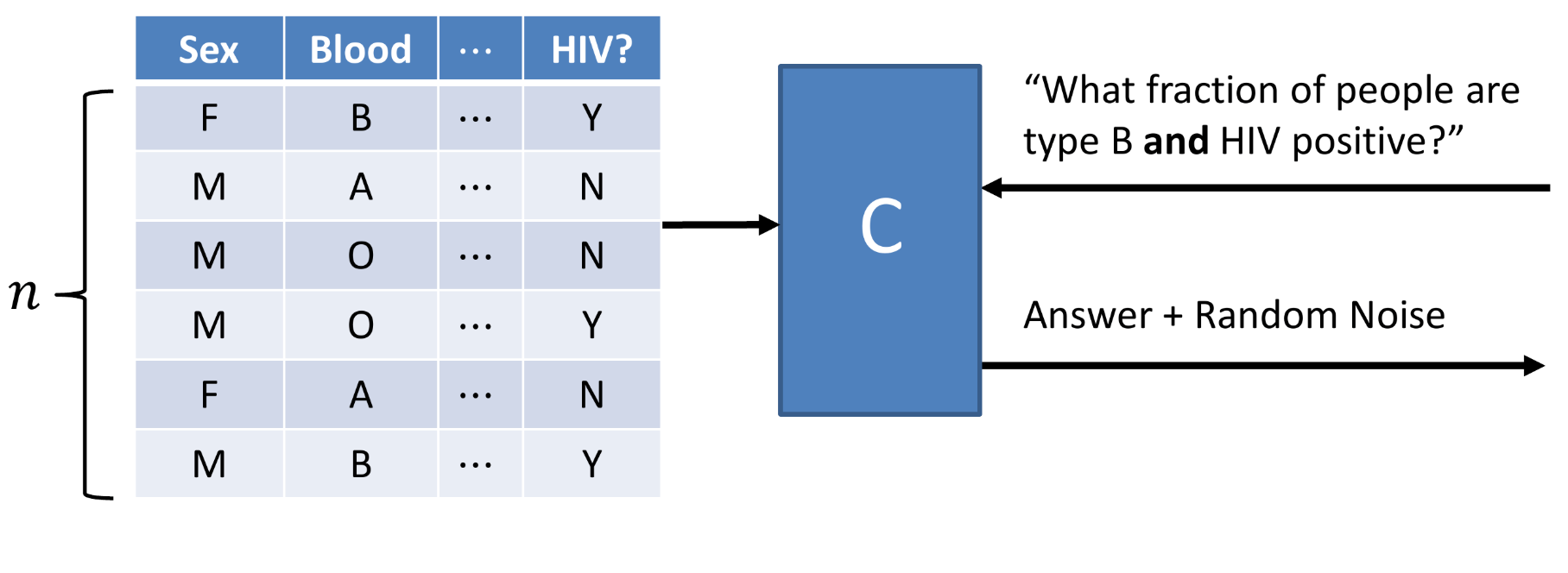
Let’s imagine that our data analyst asks the curator what fraction of the people in the dataset are HIV positive and have a blood type that is type B. A differentially private system would respond to this question and would add a known level of random noise to the data. The algorithm is transparent, so the data analyst is allowed to know exactly what distribution this random noise is sampled from, and it makes no difference to the algorithmic privacy.
The amount of noise needed to be added to ensure that if one individual is removed from a dataset, the data analyst would not be able to tell is of the order of 1/n, where n is the number of people in the dataset. This should make sense since a noise level of 2/n would mean that an analyst could not tell if an individual’s data was changed, added, or removed, or it was a function of the noise added to the dataset.
As the number of individuals in the dataset increases, the amount of noise that must be added to protect the privacy of a single individual gets progressively smaller.
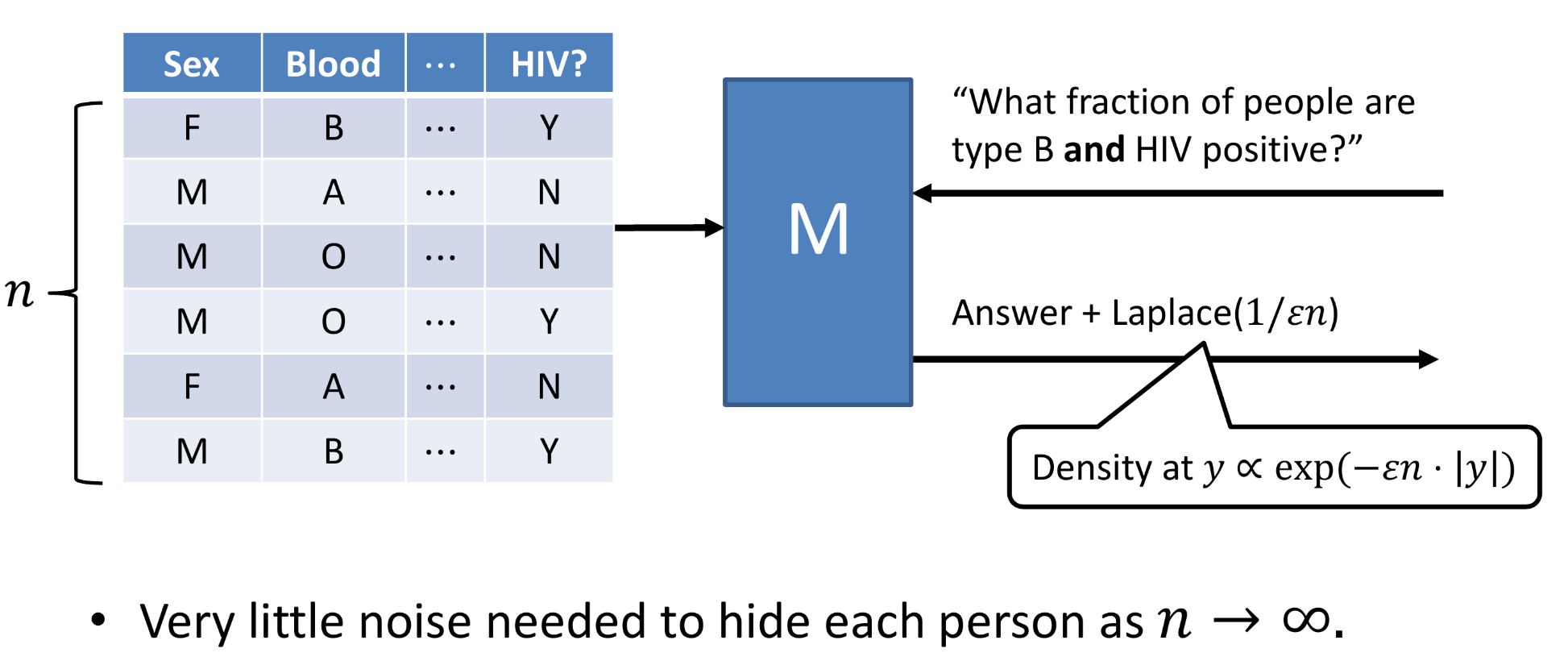
The noise added is typically of the form of a Laplace distribution, and the level of privacy can be controlled with our ‘privacy parameter’ which we call ϵ. We can think of this value as the difference between two datasets that differ only in one way: that an individual X is present in one of the datasets and not in the other.
The intuitive definition of the privacy parameter.
When the value of ϵ is very small, we have greater privacy — we are effectively adding a larger amount of noise to the dataset to mask the presence of specific individuals. When the value of ϵ is very large, we have weaker privacy. Typically, the value of ϵ is less than 1, and is usually closer to zero and around 0.01–0.1.
What has been created here is an algorithm that ensures that whatever an adversary learns about me, it could have learned from everyone else’s data. Thus, inferences such as whether there is a link between smoking and lung cancer would still come up clearly in the data, but information about whether a specific individual smokes or has cancer would be masked.
How does this work for datasets which allow multiple queries to be asked?
This is an important question: if I ask enough questions to the dataset, will it eventually confess everyone’s information to me? This is where the concept of the privacy budget comes in.
The ‘mechanism’ (our data curator that interacts with the database and data analyst) is constrained from leaking individual-specific information. Each time you ask a question and it responds to your query, you use up some of your privacy budget. You can continue to ask questions about the same group of data until you reach the maximum privacy budget, at that point the mechanism will refuse to answer your questions.
Notice that this does not stop you from ever asking a question about the data ever again, it means that the mechanism will enforce that the data you access must have a new amount of noise added to it to prevent privacy leaks.
The reason the concept of the privacy budget works is that the notion of the privacy parameter composes gracefully — privacy values from subsequent queries can simply be added together.
Thus, for k queries, we have a differential privacy of kε. As long as kε < privacy budget, the mechanism will still respond to queries.
Hopefully, by this point you are coming to realize the implications of such a mathematically assured privacy algorithm, and now understand why it is superior to the notions of k-anonymity, l-diversity, and t-closeness. This has been implemented by companies in different forms, and we will quickly look at the differences between the formulations.
Global Differential Privacy
This is the most intuitive form of differential privacy that I alluded to in the examples above, where the database is managed by a company or government curator in a centralized (single) location.
As an example, the US Census Bureau is planning to use global differential privacy for the 2020 US Census. This means the bureau will get all of the data and place it into a database unadulterated. Following this, researchers and interested parties will be able to query to census database and retrieve information about census data as long as they do not surpass their privacy budget.
Some people are concerned by global differential privacy, as the data exists at its source in raw form. If a private company did this (Uber is currently the only company I am aware that uses global differential privacy), then if that data is subpoenaed, the company would have to hand over sensitive information about individuals. Fortunately, for the US Census Bureau, they take a vow when joining the bureau to never violate the privacy of individual’s through census data, so they take this pretty seriously. Additionally, the bureau is not allowed to be subpoenaed by any government agencies, even agencies such as the FBI or CIA, so your data is in fairly safe hands.
Local Differential Privacy
This form of differential privacy is used by Google in their RAPPOR system for Google Chrome, as well as Apple IPhones using IOS 10 and above. The idea is that information is sent from an individual’s device but the noise is added at the source and then sent to Apple or Google’s database in its adulterated form. Thus, Google and Apple do not have access to the raw and sensitive data, and even if they are subpoenaed and that data was acquired by someone else, it would still not violate your privacy.
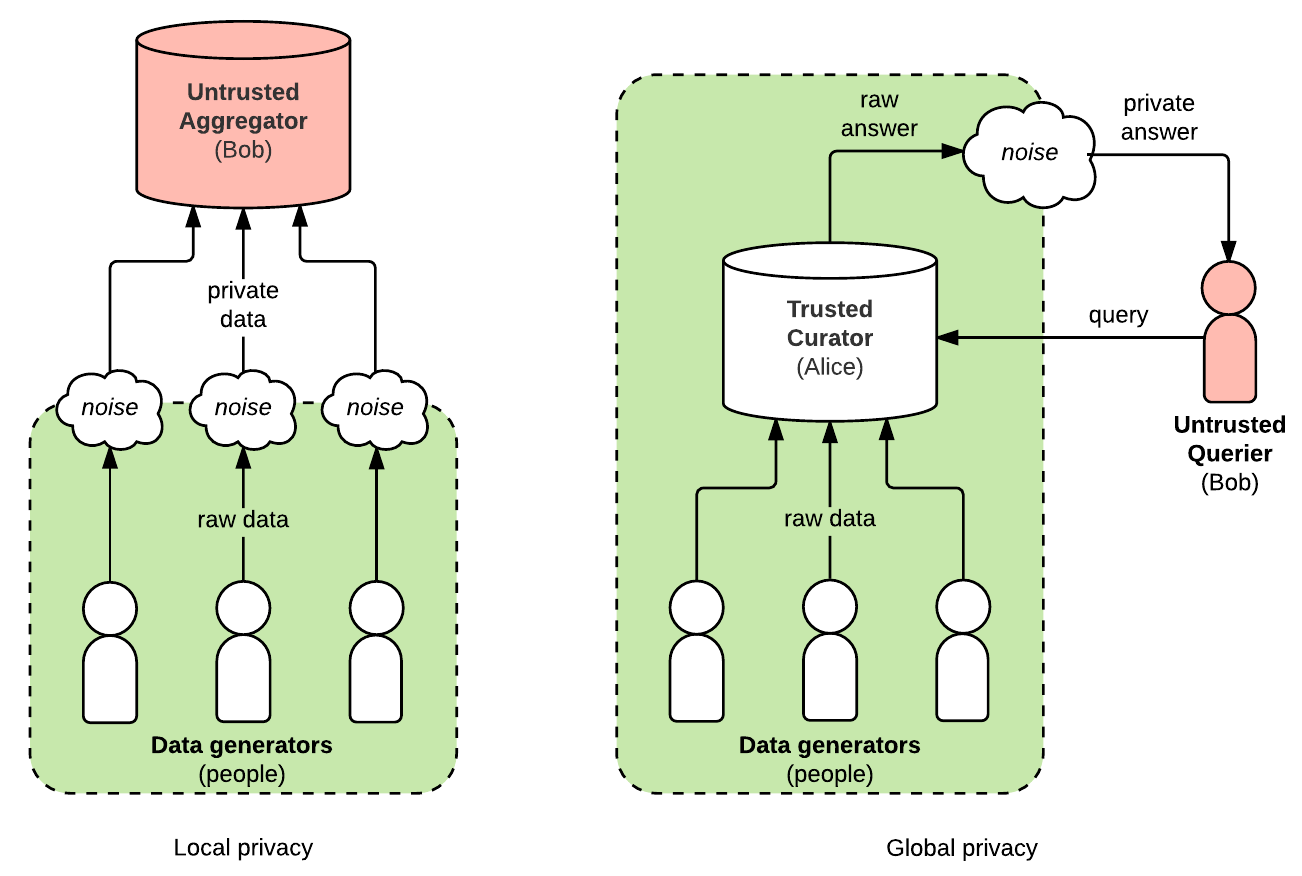
The difference between local and global differential privacy. Source
Final Comments
Congratulations on getting to the end of the article! This has been quite a deep dive into data privacy and I urge you to keep up to date on what is happening in the privacy world — knowing where and how your data is used and protected by companies and governments is likely to become an important topic in the data-driven societies of the future.
“To be left alone is the most precious thing one can ask of the modern world.” ― Anthony Burgess