Ready to learn Data Science? Browse Data Science Training and Certification courses developed by industry thought leaders and Experfy in Harvard Innovation Lab.
Jupyter Notebook (or Colab, databrisk’s notebook etc) provide a very efficient way for building a project in a short time. We can create any python class and function in the notebook without re-launching kernel. Helping to shorten the waiting time for that. It is good for small-scale project and experiment. However, it may not good for long-term growth.
After reading this article, you will understand:
- When do we need to have a well-defined project folder structure?
- Modularization
- Recommendation
When do we need to have a well-defined project folder structure
Proof of Concept (PoC)
Intuitively, velocity is the major consideration when we are doing Proof of Concept (PoC). When working on one of the previous project, I explore whether or not text summarization technique can be applied to my data science problem. I do not intend to build any “beautiful” or “structure” for my PoC because I do not know it will be useful or not.
In other words, I use “quick-and-dirty” way to the PoC as no one care whether it is well structured or the performance is optimized. From a technical view, I may create a function inside Notebook. The benefit is that I do not need to handle any externalize file (e.g. loading another python file).
Packaging Solution

“four brown gift boxes on white surface” by Caley Dimmock on Unsplash
After several runs of PoC, solution should be identified. Code refactor is necessary from this moment due to multiple reasons. It does not just organized it well but it benefit to achieve a better prediction.
Modularization

“editing video screengrab” by Vladimir Kudinov on Unsplash
First, you have to make your experiment repeatable. When you finalized (at least the initial version), you may need to work with other team members to combine result or building an ensemble model. Other members may need to check out and review your code. It is not a good idea if they cannot reproduce your work.
Another reason is hyper parameter tuning. I do not focus on hyper parameter tuning in the early stage as it may spend too many resource and time. If the solution is confirmed then it should be a good time to finding a better hyper parameter before launching the prediction service. Not only tuning a number of neuron in a neural network on a dimension of embeddings layer but also different architecture (for instance, comparing GRU, LSTM and Attention Mechanism) or other reasonable changes. Therefore, modularized your processing, training, metrics evaluation function are important steps to manage this kind of tuning.
Furthermore, you need to ship your code to a different cluster (e.g. Spark, or self-build distributed system) for tuning. Due to some reasons, I did not use dist-keras (distributed Keras training library). I built a simple cluster by myself to speed up the distributed training while it can support Keras, scikit-learn or any other ML/DL libraries. It will be better to package implementation into python instead of notebook.
Recommendation
After delivered several projects, I revisited papers and project structure template and following Agile project management strategy. I will shape my project structure as the following style. It makes me have a well-organized project and much less pain in every project iteration or sprint.
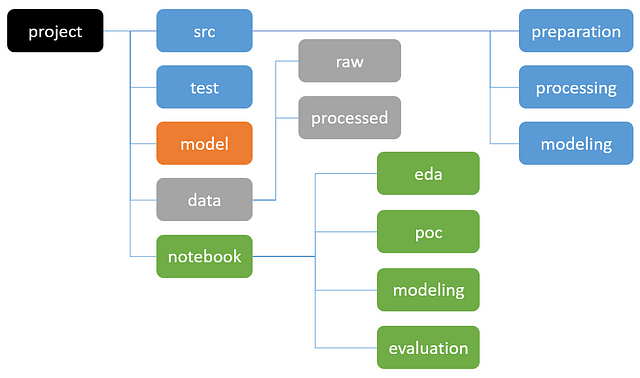
Rounded rectangle means folder. python code, model file, data, and notebook should be put under the corresponding folder.
src
Stores source code (Python, R etc) which serves multiple scenarios. During data exploration and model training, we have to transform data for the particular purpose. We have to use the same code to transfer data during online prediction as well. So it better separates code from notebook such that it serves a different purpose.
- preparation: Data ingestion such as retrieving data from CSV, relational database, NoSQL, Hadoop etc. We have to retrieve data from multiple sources all the time so we better to have a dedicated function for data retrieval.
- processing: Data transformation as source data do not fit what model needs all the time. Ideally, we have clean data but I never get it. You may say that we should have data engineering team helps on data transformation. However, we may not know what we need under studying data. One of the important requirement is both off-line training and online prediction should use the same pipeline to reduce misalignment.
- modeling: Model building such as tackling a classification problem. It should not just include model training part but also evaluation part. On the other hand, we have to think about multiple models scenario. A typical use case is an ensemble model such as combing Logistic Regression model and Neural Network model.
test
In R&D, data science focus on building a model but not make sure everything works well in an unexpected scenario. However, it will be a trouble if deploying the model to API. Also, test cases guarantee backward compatible issue but it takes time to implement it.
- Test case for asserting python source code. Make sure no bug when changing the code. Rather than using manual testing, automatic testing is an essential puzzle of a successful project. Teammates will have the confidence to modify code assuming that test case help to validate code change do not break the previous usage.
model
Folder for storing binary (json or other formats) file for local use.
- Storing intermediate result in here only. For long-term, it should be stored in a model repository separately. Besides the binary model, you should also store model metadata such as date, size of training data.
data
Folder for storing subset data for experiments. It includes both raw data and processed data for temporary use.
- raw: Storing the raw result which is generated from “preparation” folder code. My practice is storing a local subset copy rather than retrieving data from remote data store from time to time. It guarantees you have a static dataset for rest of action. Furthermore, we can isolate from data platform unstable issue and network latency issue.
- processed: To shorten model training time, it is a good idea to persist processed data. It should be generated from “processing” folder.
notebook
Storing all notebooks including EDA and modeling stage.
- eda: Exploratory Data Analysis (aka Data Exploration) is a step for exploring what you have for later steps. For a short-term purpose, it should show what you explored. A typical example is showing data distribution. For long-term, it should store in a centralized place.
- poc: Due to some reasons, you have to do some PoC (Proof-of-Concept). It can be shown in here for a temporary purpose.
- modeling: Notebook contains your core part which including model building and training.
- evaluation: Besides modeling, evaluation is another important step but lots of people do not aware of it. To get trust from the product team, we have to demonstrate how good does the model.
Take Away
To access the project template, you can visit this github repo.
- Aforementioned is good for small and medium size data science project.
- For large scale data science project, it should include other components such as feature store and model repository. Will write a blog for this part later.
- Modified it according to your situation.