Ready for Big Data Training & Certification? Browse courses like Big Data – What Every Manager Needs to Know developed by industry thought leaders and Experfy in Harvard Innovation Lab.
Busting Myths about the Best Node Size for Big Data
It’s been about ten years since NoSQL showed up on the scene. With its scale-out architecture, NoSQL enables even small organizations to handle huge amounts of data on commodity hardware. Need to do more? No problem, just add more hardware. As companies continue to use more and more data, the ability to scale-out becomes more critical. It’s also important to note that commodity hardware has changed a lot since the rise of NoSQL. In 2008, Intel was about to release the Intel Core and Core Duo architecture, in which we first had two cores in the same die. Jump back to the present, where so many of us carry around a phone with an 8-core processor.
In this age of big data and powerful commodity hardware there’s an ongoing debate about node size. Does it make sense to use a lot of small nodes to handle big data workloads? Or should we instead use only a handful of very big nodes? If we need to process 200TB of data, for example, is it better to do so with 200 nodes with 4 cores and 1 terabyte each, or to use 20 nodes with 40 cores and 10 terabytes each?
There are well-documented advantages to bigger nodes. In a cloud environment, you’re less prone to the noisy neighbors problem. In fact, after a certain size, you’re likely the only tenant in the box. Having fewer-but-bigger nodes simplifies operations. Yet we still see a lot of systems awash in a sea of small nodes. Why? One reason we hear is that having all this processing power doesn’t really matter because it’s all about the data. If nodes are limited to a single terabyte, increasing processing power doesn’t really help things and only serves to make bottlenecks worse.
We’ll take a closer look at that line of reasoning in a bit. But first let’s look at today’s hardware. The image below shows the Amazon EC2 I3 family. As you can see, the number of CPUs spans from 2 to 64. You’ll also notice that the amount of memory of those machines grows proportionally, reaching almost half a terabyte with the i3.16xlarge instance. Similarly, the amount of storage grows from half a terabyte to more than 15 terabytes.
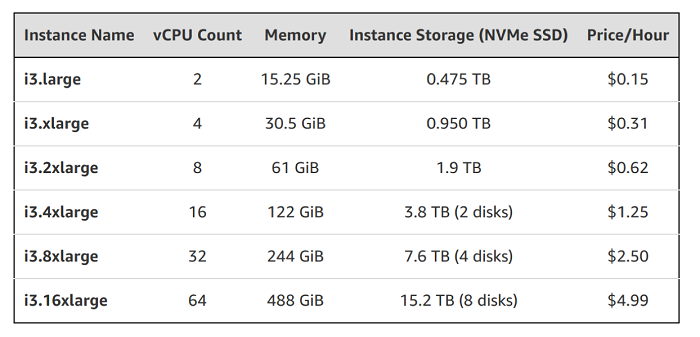
The Amazon EC2 I3 family
Note that for the first three options in this family, storage grows by getting a bigger disk. When we get to the i3.4xlarge instance in the middle we get 2 disks, the i3.8xlarge gets 4 and the i3.16xlarge gets 8 disks that are now in an array. So we have more storage space and the disks are also getting faster. SSDs are very parallel. Now we’ve got more CPUs, more memory, more and faster disks and the price doesn’t change. So we see here that no matter how you organize your resources–the number of cores, the amount of memory and the number of disks–the price to use those resources in the cloud will be about the same. Other cloud providers have very similar offers.
The Search for an Inflection Point
One of the first things we need to find out is where our software stack stops scaling. If we double our available resources and see little or no increase in speed, then regardless of any other considerations we shouldn’t scale up past that point.
Of course, the only way to really understand what’s going on is to do some experiments. So that’s what we did in our search for an inflection point. We used our Scylla NoSQL database to conduct these tests. Full disclosure, NoSQL databases are not created equal and I’ll point out some of the differences as we go.
We started with a single cluster with three machines from the I3 family: The i3.xlarge, with 2 CPUs and roughly 15GB of RAM. We had those three nodes work as replicas of each other, so our replication factor was 3. The experiment consisted of inserting 1,000,000,000 partitions as fast as possible to that cluster using a single loader machine. Through the experiment, we moved up in the I3 family, doubling the resources available to the database at each step. We also increased the number of loaders, doubling the amount of partitions and the data set size at each step.
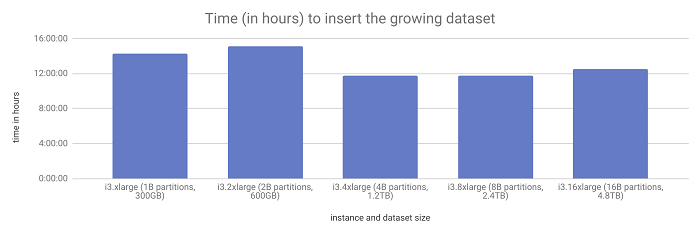
The time to ingest the workload did not change as the data set grew from 300GB to 4.8TB.
In the first test, with the i3.xlarge cluster, it took 14 hours, 20 minutes of total operation time to insert 1,000,000,000 partitions into this cluster.
We doubled everything for the second test. Our cluster was still 3 nodes but was now running i3.2xlarge machines that are twice as powerful. And we had two clients writing a total of 2,000,000,000 partitions (each writes 1,000,000,000 in a disjoint set). Yet this test took only 6% longer to complete. The time was relatively constant.
Next was a cluster of i3.4xlarge machines writing a total of 4,000,000,000 partitions. When we reached this size some interesting things started to happen. As we mentioned earlier, those machines are less prone to noisy neighbor problems. We also started specializing. For example, to make the network faster we assigned certain CPUs to handle only interrupt processing. We also see that those disks are getting faster. Put all that together and we got 22% faster than before. This is a clear win, yet we still need to find the point at which it is no longer worthwhile to add more resources to the same hardware.
Moving on, for the i3.8xlarge and 8,000,000,000 partitions we see a 5% increase in time over the previous experiment. And for the i3.16xlarge and 16,000,000,000 partitions, we see an increase in execution time of just 6% where we once again grew the data set by a factor of two.
So what did we learn here? The the time it takes to ingest this workload didn’t change much–even when the total data size reached about 4.8TB. So if your software has linear scale-up capabilities, it makes sense to scale up before scaling out.
The Compaction Conundrum
If you come from a Cassandra background, you’re probably thinking “good luck compacting that!” We have a node with almost 5TB and it’s going to take forever to compact. This is another argument that’s used against big nodes.
If you don’t have experience with Cassandra, here’s a quick primer on compactions. As we write things into the database those writes go a memory structure called a Memtable and in parallel to a commit log in case the node fails. Every once in a while, this Memtable is flushed to an immutable data structure called the SSTable. Reading from a lot of files is expensive, so every once in a while a background process called compaction has to run. It takes a number of SSTables and folds them into fewer SSTables.
This process tends to be both slow and painful. If compactions are too slow, reads suffer. If they’re too fast, the foreground workloads suffer, since their resources are depleted. To avoid that, the user has to set how many compactions will run in parallel and the maximum compaction throughput the system can sustain. The problem is, it can be very hard to get all this right, especially for workloads that tend to change a lot during the day. It puts an artificial limit on how fast compactions can go that is potentially independent from the hardware power. So if the dataset grows, compaction times will surely follow.
However, there are ways to get around the artificial limitation of the compaction throughput by automatically determining what the optimal rate should be at every point. Databases that can do that–with compactions and other processes–are said to have autonomous operations.
Equipped with its own I/O Scheduler or other similar technologies, a database can avoid sending more requests to the disk than the maximum useful disk concurrency. Rather than being queued in the disk, requests are queued inside the database, where they are tagged as query requests, commit log requests, compaction requests, and so on. That way compactions can be unleashed at full speed, and any latency-sensitive queries can be served through the query log.
Once we get rid of artificial limitations in the compaction bandwidth, we have more CPUs and more, faster disks. We should be able to compact this data set faster as well since compaction is a process that uses those two resources–CPU and disk. Truth or myth? Time for another experiment! For this experiment, we used the same cluster as in the previous experiment and called nodetool compact in one of the nodes. Nodetool compact is a tool that will compact every SSTable into a single one.
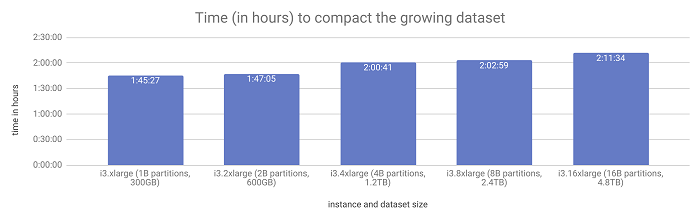
Compaction times remained level as the data set doubled with each successive test.
As you see in the results above, compacting a data set of 300GB and compacting a data set of almost 5TB takes about the same amount of time as long as all the resources in the machines are scaling up proportionately.
Node Size and Failures
Lastly, another very common argument for using small nodes are failures. The thinking is to avoid having to replace a node with 16TB of disk. Better to transfer a terabyte or less, right? This certainly sounds true, but is it? Truth or myth?
Having more processing power and having more and faster disks made compactions faster. So why wouldn’t that also be the case for streaming data from one node to another? The one potential bottleneck, aside from artificial limitations, is the network bandwidth. But streaming data is seldom bottlenecked by the network. If it were, we would be able to transfer 5TB of data in around half an hour anyway — as the i3.16xlarge from AWS have 25Gbps network links.
We need to find the real cost of streaming. To do so, we did yet another experiment. Using the same clusters as before, we destroyed the node we’d just compacted and rebuilt it from the other two. You can see in the results below that it takes about the same amount of time to rebuild a node from the other two, regardless of the dataset size. It doesn’t matter if it’s 300GB or almost 5TB. If the resources keep scaling linearly, so does the total time of this operation. Our experiment busts that myth.
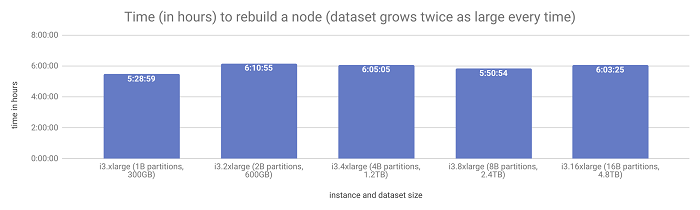
The time to rebuild a node also remained the same despite the growing data set.
Also, the real cost of failures is much more complex than simply the time it takes to stream data. If the software stack scales well, we saw that it isn’t more expensive to restore a bigger node. But even if that were the case, the median time between failures tends to be a constant, so if you have twice the number of nodes you will have twice the number of failures. Remember that for most organizations a failure in the data layer requires some form of human interaction.
So with fewer, bigger nodes, there are less failures and it costs about the same to recover from each one. That’s a clear win. Another aspect of failures is that databases with autonomous operations should be able to keep SLAs in the face of failures. One example of how that can be achieved is through the use of Schedulers–same as we saw for compactions. In that case, the time it takes to recover a node matters little.
Conclusions
Based on the results of our experiments, we see that the arguments in favor of using smaller nodes do not always hold up. However, the capabilities of your database factor heavily into all of this. Ask yourself, does your database scale linearly with the amount of resources in the machine? Does that linear scalability also reflect on background processes like compaction? And does it have the facilities to help the cluster continue to meet its SLAs during failures? If the answer to these questions is yes, there’s no real advantage to using small nodes to do big data. You can avoid adding unnecessary complexity to your system, reduce operational overhead and lower the frequency of failures by scaling up before scaling out.
First appeared on InsideBigData