The short answer is yes. As long as there is ‘data’ in data scientist, Structured Query Language (or see-quel as we call it) will remain an important part of it. In this blog, let us explore data science and its relationship with SQL, including answers to the 5 Ws and 1 H – how, why, where, when, who and what. We will also learn the basics of Database Management Systems (DBMS) and understand how being a data scientist could be the best choice for your career.
What is data science?
Data science is broad in its perspective and a data scientist requires deep knowledge of one or more of the various streams of mathematics, machine learning, computer science, statistical research, data processing and of course domain expertise. Each of these streams needs extensive work with data, be it collection, analysis or processing. If you are preparing for a data science interview, go through these essential data science interview questions.
Why is data science so popular?
The digital world is at its peak, and with growing demands and extensive marketing strategies data has become the key to all marketing purposes. For example, if I want to buy a new phone, I go to online shops like Amazon or Flipkart, browse through different brands, put a few in my cart, but decide to buy it later after some more research. Internally, the online shop would save my shopping cart and browsing history and show me suggestions for more phones when I come back later. Even if I don’t buy, the company would send me emails to remind me that my shopping cart is “still waiting for me.” Data, thus plays the most important role in creating a relationship between buyer and seller. The more data customer shells out, the more customized a stream is presented to the buyer. This is not just true for e-commerce, but data science is proving extremely useful in many other domains like healthcare, manufacturing, banking, finance and transport.
How?
Collection – Suppose you are at IKEA and checking out a fitted sheet. You buy the product and leave. Later you realize you want more of the same product and come back. You tell your friends how useful and inexpensive the product is and they are convinced to buy it too. Manufacturers use this data to understand the likes of customers and update their inventory to have more of the products that are popular. Further, constant feedback helps them bring improvements to their existing product.
Processing – The data from users is collected, and during the modelling and planning stage actionable insights are taken into account. For example, more customers looking for a particular colored fitted sheet or a specific cloth for their curtains.
Analysis – Imagine you bought a blue color fitted sheet, but realize for your room’s ambiance that green would be a better choice, which is not available currently. Green is a common, popular color. With the analysis of human inputs and data management tools, it can be determined whether or not introducing a green fitted sheet would be a good idea, if it will serve the purpose of more customers, and bring more profit.
For demand forecasting and inventory management, we need to store all the user information including their purchases, likes and dislikes, feedback, etc. somewhere.
Where?
Yes, you got it – everything is stored in a database. SQL is thus vital for handling humongous amounts of data that need to be processed on a regular basis. It also acts as an important tool for the right marketing and feedback that data science intends to do. For example, if you don’t like a video that Facebook is suggesting you – you would say ‘hide this’ and Facebook will immediately ask you for a reason. These user preferences also need to be stored somewhere.
Through a relational database like SQL, data science provides a continuous system to process and improve the way data is presented and handled.
Where does SQL fit in?
SQL is an important part of the entire data science universe. But, where exactly does it fit in? If you want to be a data analyst, data engineer or data architect, you will need to learn SQL along with programming languages like C, R and Python. Here is a simple diagram that shows the stages where SQL is used:
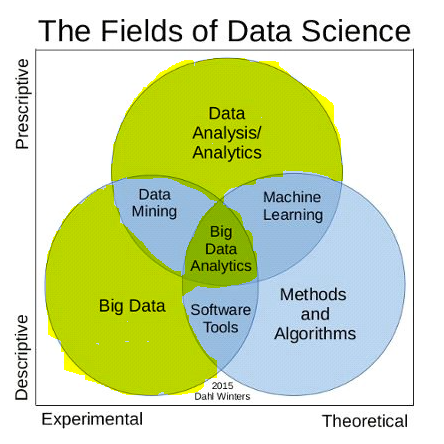
For original image source, click here.
The highlighted portion is where we need SQL knowledge: big data, big data analytics and data analysis.Why SQL?
Though there are NoSQL databases that offer high performance and speed, SQL databases are still most widely used for all practical purposes. There are more developers who understand SQL technology and hence the support and documentation are more plentiful. Further, data integrity is one key factor that makes SQL stand apart from any NoSQL database, by way of the assurance that no duplicates or unauthorized data can enter the system. Also, for complex queries and joins, a well-structured relational database works better.
What is SQL?
SQL is a relational database management system used for storing, retrieving, updating and reading data from the database. If you get introduced to SQL from the basics through this beautifully designed course, you will love SQL for life.
For this blog, we will concentrate on how SQL matters to data science. Let us take a simple example of how you as a data scientist could possibly use SQL to collect and analyze data.
Suppose you want to know the popularity of a book named ‘The Data Science Handbook’ by the author ‘Carl Shan’ by checking how many users ordered a copy of it. Because SQL is a well-structured language with a proper schema, you could have a structure like this:
customer table – customer_id, customer_name, order_id, etc.order_details table – order_id, order_desc, order_date, etc.book table – book_id, book_name, author, order_id, etc.
order_id is common to all the three tables and using this data, we can write a query to fetch the necessary details.
In real-life scenarios, this kind of system can be at multiple levels, where huge data needs to be analyzed and worked upon. Everyday data from millions of users is stored and analyzed for various purposes.
Imagine doing all this without the use of SQL; is it even thinkable?
While some people want to believe that SQL’s role in a data scientist’s job is reducing, that is not the case. SQL is here to stay.
Here are some key SQL concepts that a data scientist should know:
Relational database model
In a relational database model, all the data points are related or connected to each other. While creating this kind of database, the relationships between various tables and columns has to be defined in the design stage itself. In our above example, the three tables are related. The customer table’s primary key (“a specific choice of a minimal set of attributes (columns) that uniquely specify a tuple (row) in a relation (table)”) will be
customer_id, whereas order_id will be a foreign key (“set of attributes subject to a certain kind of inclusion dependency constraint, specifically a constraint that the tuples consisting of the foreign key attributes in one relation, R, must also exist in some other (not necessarily distinct) relation, S”). In the same way, the book_id and order_id combined can be the composite key for book table. These relations have to be defined during the creation stage itself. DBMS Normalization
Normalization is the design process where tables in the database are organized in such a way to avoid redundancy and dependency of the data. Using normalization of different forms, we can divide data into smaller structures and establish links between them so that the data is optimally stored. This nice article presents information about normalization in a very simple and understandable manner.
Database schema
Database schema is the logical view of a database. All the relations like constraints, tables, views, triggers etc. that are applied on the data form the schema.
Basic SQL commands
SQL can execute the following types of statements:
- DML (Data Manipulation Language) statements –
select, insert, delete, update - DDL (Data Definition Language) Statements –
create, drop, alter - DCL (Data Control Language) Statements –
grant, revoke - TCL (Transaction Control Language) Statements –
begin, commit, rollback
Who should learn SQL?
By now, you should understand that if you are crazy about data and playing with it, and want Data Science as your career choice, you should definitely learn SQL.
Data scientist as a career choice
Loads of data is generated every day and needs to be converted into new business solutions, designs, and products which can only come from the creative mind of a data scientist. This need will only increase by the day at least for a few decades. In addition to the fat package that the industry offers to a data scientist, it is the challenge and ever-growing roles that attract professionals towards this job. From data administrator, data architect, data analyst, business analyst to a data manager or business intelligence manager, there are plenty of opportunities to choose within the data science circle. Knowledge of SQL, programming languages like R and Python, statistics and applied math, paired with critical thinking and industry knowledge will get you there sooner than you would think.
This article has originally appeared in KDnuggets.