Top articles, research, podcasts, webinars and more delivered to you monthly.

The Limitations of Machine Learning
Machine learning is now seen as a silver bullet for solving all problems, but sometimes it is not the answer....
Machine learning is now seen as a silver bullet for solving all problems, but sometimes it is not the answer....

This is a comprehensive tutorial on handling imbalanced datasets. Whilst these approaches remain valid for multiclass classification, the main focus...

Tiny machine learning (tinyML) is the intersection of machine learning and embedded internet of things (IoT) devices. The field is...
Understanding and combating issues of fairness in supervised learning. “Being good is easy, what is difficult is being just.” ― Victor Hugo...
This article is meant to condense and summarize the field of interpretable machine learning to the average data scientist and...

This article takes you to a deep dive into data privacy and urges you to keep up to date on...

Machine learning in science does present problems in academia due to the lack of reproducibility of results. However, scientists are...
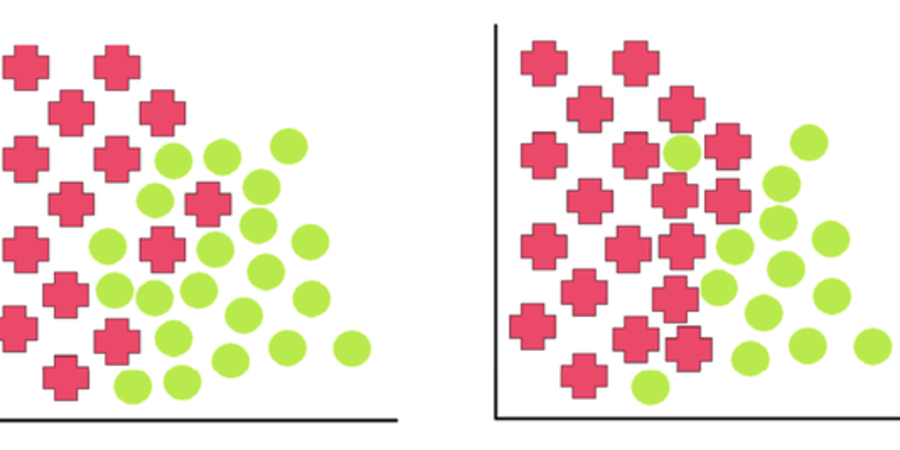
Dataset shift is a topic that is extremely important and yet undervalued by people in the field of data science...

The future of computation looks like it will involve speeding up computations to handle the relentless and exponential increase in...

The importance of visualization is a topic taught to almost every data scientist in an entry-level course at university but...

If machine learning and statistics are synonymous with one another, why are we not seeing every statistics department in every...