Ready to learn Machine Learning? Browse courses like Machine Learning Foundations: Supervised Learning developed by industry thought leaders and Experfy in Harvard Innovation Lab.

This is a continuation of the three part series on machine learning for product managers.
The first note focused on what problems are best suited for application of machine learning techniques. This note would delve into what additional skill-sets a PM needs when building products that leverage machine learning
As I had mentioned in Part I, the core skill sets required of a PM do not change whether you work in a machine learning driven solution space or not. Product managers typically use five core skills — customer empathy/design chops, communication, collaboration, business strategy and technical understanding. Working on ML will continue to leverage these skills. One area that does get stretched more is technical understanding, specifically of the machine learning space. It’s not to say that you cannot be a ML PM unless you have deep technical chops. But you do need to understand how a machine learning system operates in order to make good product decisions. You can lean on your engineers or shore up your knowledge through books and courses, but if you don’t have a good understanding of the system, your product may lead to bad outcomes.
Algorithms have limitations
Every algorithm or technique used in machine learning is optimizing for a certain task and is not always able to take into account the various nuances that real world situations entail. Being able to understand the impact and limitations of the algorithms, helps you understand what gaps would exist in the customer experience and solve for those gaps through product design or by choosing other ML techniques. This is an absolutely necessary skill-set if you are a PM in this space. Let me give you a few examples.
Biases in data
Machine learning algorithms learn patterns from data. Hence, the quality of the data fed to the algorithms determines the success of the product. One of the first challenges of building a machine learning product is to ensure that the data is representative of the users who will use the product.
Remember when Google tagged photos of black people as gorillas.


jackyalciné ez de nu blick penthe@jackyalcine
Google Photos, My friend's not a gorilla.
Ensuring you represent all your users in the data is fundamental to the success of the product.
Sometimes, these biases may exist, not because of mistakes in data collection, because of biases in data availability as well. For example, when IBM Watson was being trained to learn language, and it was fed the Urban Dictionary, it learned to swear. The intended outcome was to learn ‘polite ’human language, but instead because the data also had swear words, the machine learned that too. Hence, it required cleaning up of the data before re-training Watson.
Another example. It’s likely that more users in the developed economies access the internet, than in developing economies. Hence, if you model, say search behavior based off of searches on the internet, it would have a higher distribution of users from developed economies. Thus, when you model the patterns of search, it may not be very accurate for users who don’t search often enough, say first time Internet users in India. Being cognizant of the biases in data would help you be aware of the unintended effects these algorithms may have on user experience.
Tradeoff between precision and recall
Recently, I was in talks with a team at work that was using the exact same prediction product as my team but the objectives of both teams were different. The product provided predictions of bad behavior. My team cared about ensuring that only bad actors, and no good actors were filtered out by the system. We wanted every good actor to be able to use the feature. So, we cared about precision. The other team cared that no bad actor was allowed to use the product, even if that meant a few good actors were also restricted from using the product. So, they cared about recall. Precision and recallalways trade-off against each other. If you increase precision, your recall would be lower and vice-versa.
Figuring out if your use-case requires more emphasis on precision or recall changes the tuning of the models the engineers would choose. Hence, it’s important to be very deliberate about what’s needed to solve the user problem. Trade-off curves similar to the one below are used to review the metrics related to the models you are using.
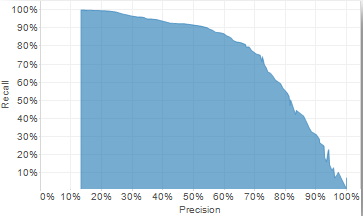
Precision-Recall curve
Depending on the requirements of the problem, the models can be tuned to be anywhere on this frontier. Sometimes, if you need to change the frontier itself, then you might need to choose different machine learning models (which may come with other limitations)
Cold start problem
Machine learning algorithms require data to be able to do pattern recognition. Cold start is a term used in cars when the engine is cold and the car may not function optimally. However, once the engine is up and running, you are good to go. Similarly, there are scenarios when the algorithms don’t have any data on the user or an item and have cold start issues leading to sub-optimal experiences.
Cold start problems are of two types
User based : This is when the user is using your product for the first time, and the models have no signal on the user. Take the example of Netflix. Netflix provides you recommendations of shows and movies to watch based on your watch history. But, the very first time you use Netflix, it has no data on your watch behavior and hence, it’s very hard for the algorithms to predict what your viewing preferences are.
This problem can be solved in several ways. A few commons ones are
- You prompt the user to give you data by choosing a few favorite movies from a random selection
- You can provide a best effort recommendation using some basic signals you may have about the user — say looking at where the user is logging in from, and making an assumption that the user might like movies that other users in that location like. For example, if you are logging in from California, you might show the top 10 shows that other users from California watch
- Curation. You may have a manually curated golden set, say all-time favorite movies, that you can show as a starting experience.
Item based: This is when an item is being provided to your users for the first time and it’s hard to pick which users to show it to. For example, when a new movie comes to the Netflix catalog, deciding who to show it to as a recommendation is tough, especially if the meta-data on the movie is sparse. Similar to the user based cold start problem, this can be solved by a number of techniques.
- Human annotation: You can have humans annotate this item with meta-data to give you signal on what it is about. For example, you could get the new movie added to the catalog to be seen by a panel of experts who then categorize it. Based on the categorization, you can decide the group of users this movie should be shown to.
2. Algorithmically: In layman terms, algorithmic techniques work by showing the new item to a number of users to understand their preferences, thereby getting more signal on who prefers this item, and narrowing down the user segment. If you are interested in going deeper in this topic, you can check out this primer on multi-armed bandit algorithms .
In anomaly detection, cold start issues can throw off a lot of false alarms. For example, when a new employee is accessing the database systems, the ML system may consider him/her as an intruder and it may throw off a false alarm. You may have encountered this when you use a card in foreign locations when traveling, or when making a large purchase. The way to tide over this is to create mechanisms to gather feedback (either before or after the action) to correct the false positives, which brings me to the next section.
Feedback loop
As algorithms aren’t perfect, they can get their predictions and pattern recognitions wrong. You need to create mechanisms in your product to provide feedback to the algorithms, such that they can improve their accuracy over time. These feedback loops may be as simple as logging negative signals, for example, how fast did a user scroll past a news headline vs spending time reading it. You can even provide more explicit feedback loops by letting users intervene when the algorithm makes mistakes — thumbs down, crossing out, etc. or when the algorithm does a good job, allowing users to thumbs up, share, save etc.
Explore vs Exploit
Let’s take the Netflix example above to illustrate this challenge. Say, Netflix’s algorithms have figured out that I enjoy watching football. So, I see in my recommendations of movies, shows and documentaries related to football. I watch a few of those, now Netflix shows me even more content related to football and the cycle continues. The algorithms here are Exploiting the signal they have available — that I like football and thus optimizing for just that. However, there’s a lot of content outside of football that is interesting for me. I like technology too, but Netflix doesn’t show me any content related to technology. This has been referred to as filter bubbles, most recently in media.
In order to provide a balanced view of the content available to a user, the system should periodically introduce items where there’s less signal about the preferences to the user allowing for Exploration. The introduction of new content can be random( show me a few of Yoga, Food, Wildlife, Technology shows) or learned (other users who prefer football, prefer food documentaries for example).
The above is not an exhaustive list of all the limitations of algorithms, because as new algorithms come up, there might be new gaps that they expose.You might ask — how might I understand what gaps the algorithms have, especially if you don’t understand the algorithms themselves. Here’s where you put on your PM hat.
- Provide clear use-cases to your engineering team. Run through those use-cases with your engineering team explaining what the expected experience should look like for these use cases. These use-cases should include both primary, secondary and negative personas for your product. Once your models are ready, evaluate if the model outputs match the intended experiences for these use-cases.
- Pay attention to data collection. Ask questions about how the data is being cleaned and organized. Is the data representative of your user-base ?
- Plug the gaps using product solutions. If the model outputs don’t meet your expectations, figure out what you might do to either improve the ability of the model to account for these use-cases or if these use-cases stretch the machine learning capabilities of the model, then creating product solutions, filters etc. to cover for these gaps.