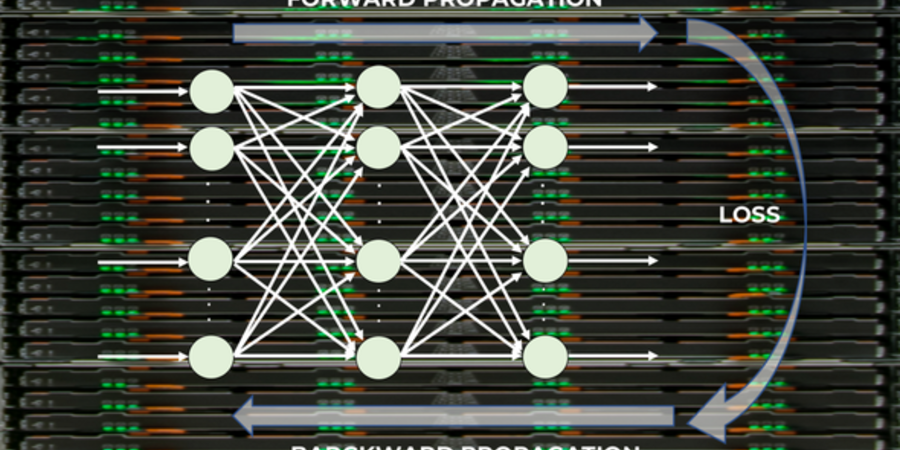




Top articles, research, podcasts, webinars and more delivered to you monthly.
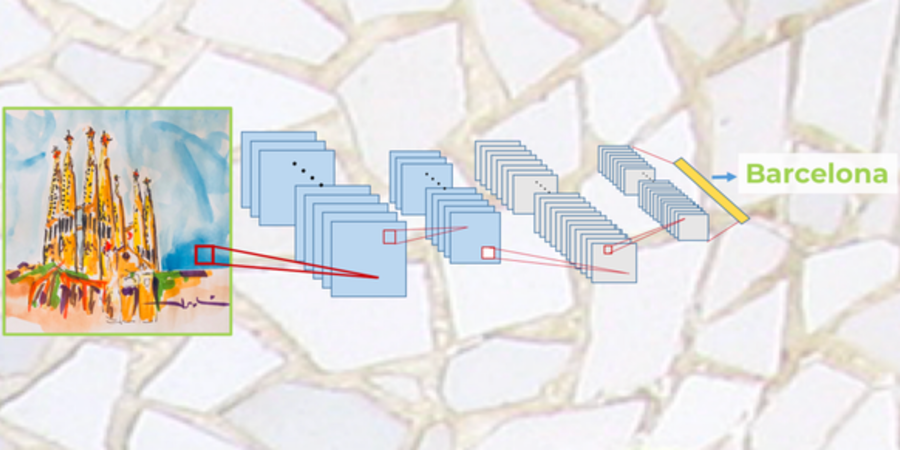
Convolutional Neural Networks for Beginners – Practical Guide with Python and Keras
Convolutional neuronal networks are widely used in computer vision tasks. These networks are composed of an input layer, an output...