Ready to learn Machine Learning? Browse Machine Learning Training and Certification courses developed by industry thought leaders and Experfy in Harvard Innovation Lab.

TPOT graphic from the docs
Automated machine learning doesn’t replace the data scientist, (at least not yet) but it might be able to help you find good models faster. TPOT bills itself as your Data Science Assistant.
TPOT is meant to be an assistant that gives you ideas on how to solve a particular machine learning problem by exploring pipeline configurations that you might have never considered, then leaves the fine-tuning to more constrained parameter tuning techniques such as grid search.
So TPOT helps you find good algorithms. Note that it isn’t designed for automating deep learning — something like AutoKeras might be helpful there.
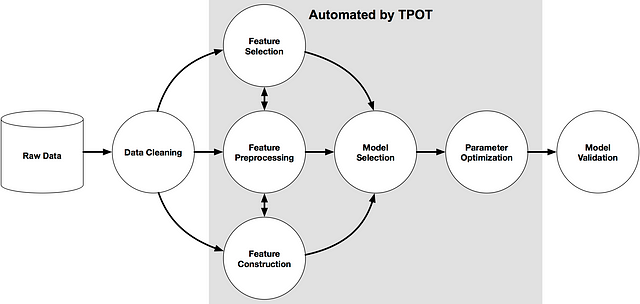
An example machine learning pipeline (source: TPOT docs)
TPOT is built on the scikit learn library and follows the scikit learn API closely. It can be used for regression and classification tasks and has special implementations for medical research.
TPOT is open source, well documented, and under active development. It’s development was spearheaded by researchers at the University of Pennsylvania. TPOT appears to be one of the most popular autoML libraries, with nearly 4,500 GitHub stars as of August 2018.
How does TPOT work?
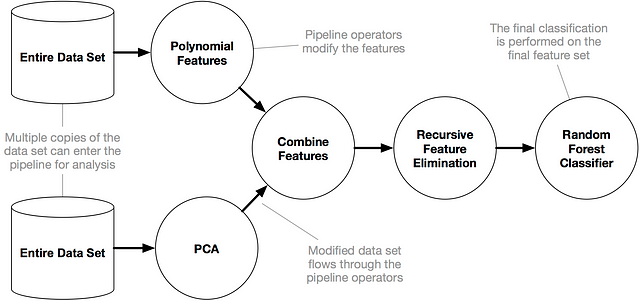
An example TPOT Pipeline (source: TPOT docs)
TPOT has what its developers call a genetic search algorithm to find the best parameters and model ensembles. It could also be thought of as a natural selection or evolutionary algorithm. TPOT tries a pipeline, evaluates its performance, and randomly changes parts of the pipeline in search of better performing algorithms.
AutoML algorithms aren’t as simple as fitting one model on the dataset; they are considering multiple machine learning algorithms (random forests, linear models, SVMs, etc.) in a pipeline with multiple preprocessing steps (missing value imputation, scaling, PCA, feature selection, etc.), the hyperparameters for all of the models and preprocessing steps, as well as multiple ways to ensemble or stack the algorithms within the pipeline. (source: TPOT docs)
This power of TPOT comes from evaluating all kinds of possible pipelines automatically and efficiently. Doing this manually is cumbersome and slower.
Running TPOT
Instantiating, fitting, and scoring the TPOT classifier is similar to any other sklearn classifier. Here’s the format:
tpot.fit(X_train, y_train)
tpot.score(X_test, y_test)
TPOT comes with its own variation of one-hot encoding. Note that it could add it to a pipeline automatically because it treats features with fewer than 10 unique values as categorical. If you want to use your own encoding strategy you can encode your data and then feed it into TPOT.
You can choose the scoring criterion for tpot.score (although a bug with Jupyter and multiple processor cores prevents you from having a custom scoring criterion with multiple processor cores in a Jupyter notebook).
It appears that you can’t alter the scoring criteria TPOT uses internally as it searches for the best pipeline, just the scoring criteria for use on the test set after TPOT has chosen the best algorithms. This is an area where some users might want more control. Perhaps this option will be added in a future version.
TPOT writes information about the best performing algorithm and it’s accuracy score to a file with tpot.export(). You can choose the level of verboseness you would like to see as TPOT runs and have it write pipelines to an output file as it runs in case it terminates early for some reason (e.g. your Kaggle Kernel crashes).
How long does TPOT take to run?

The short answer is that it depends.
TPOT was designed to run for a while — hours or even a day. Although less complex problems with smaller datasets can see great results in minutes. You can adjust several parameters for TPOT to finish its searches faster, but at the expense of a less thorough search for an optimal pipeline. It was not designed to be a comprehensive search of preprocessing steps, feature selection, algorithms, and parameters, but it can come close if you set its parameters to be more exhaustive.
As the docs explain:
…TPOT will take a while to run on larger datasets, but it’s important to realize why. With the default TPOT settings (100 generations with 100 population size), TPOT will evaluate 10,000 pipeline configurations before finishing. To put this number into context, think about a grid search of 10,000 hyperparameter combinations for a machine learning algorithm and how long that grid search will take. That is 10,000 model configurations to evaluate with 10-fold cross-validation, which means that roughly 100,000 models are fit and evaluated on the training data in one grid search.
Some of the data sets we’ll see below only need a few minutes to find algorithms that score well; others might need days.
Here are the default TPOTClassifier parameters:
population_size=100,
offspring_size=None # Jeff notes this gets set to population_size
mutation_rate=0.9,
crossover_rate=0.1,
scoring="Accuracy", # for Classification
cv=5,
subsample=1.0,
n_jobs=1,
max_time_mins=None,
max_eval_time_mins=5,
random_state=None,
config_dict=None,
warm_start=False,
memory=None,
periodic_checkpoint_folder=None,
early_stop=None
verbosity=0
disable_update_check=False
A description of each parameter can be found the docs. Here are a few key ones that determine the number of pipelines TPOT will search through:
Number of iterations to the run pipeline optimization process. Generally, TPOT will work better when you give it more generations(and therefore time) to optimize the pipeline.
Number of individuals to retain in the GP population every generation.
Generally, TPOT will work better when you give it more individuals (and therefore time) to optimize the pipeline.
Number of offspring to produce in each GP generation.
By default, offspring_size = population_size.
When starting out with TPOT it’s worth setting verbosity=3 and periodic_checkpoint_folder=“any_string_you_like” so that you can watch the models evolve and training scores improve. You’ll see some errors as some combinations of pipeline elements are incompatible, but don’t sweat that.
If you’re running on multiple cores and not using a custom scoring function, set n_jobs=-1 to use all available cores and speed up TPOT.
Search Space
Here are the classification algorithms and parameters TPOT chooses from as of version 0.9:
And TPOT can stack classifiers, including the same classifier multiple times. One of the core developers of TPOT explains how it works in this issue:
The pipeline
ExtraTreesClassifier(ExtraTreesClassifier(input_matrix, True, 'entropy',
0.10000000000000001, 13, 6), True, 'gini', 0.75, 17, 4)does the following:
Fit all of the original features using an ExtraTreesClassifier
Take the predictions from that ExtraTreesClassifier and create a new feature using those predictions
Pass the original features plus the new “predicted feature” to the 2nd ExtraTreesClassifier and use its predictions as the final predictions of the pipeline
This process is called stacking classifiers, which is a fairly common tactic in machine learning.
And here are the 11 preprocessors that could be applied by TPOT as of version 0.9.
That’s a pretty comprehensive list of sklearn ml algorithms and even a few you might not have used for preprocessing, including Nystroem and RBFSampler. The final preprocessing algorithm listed is the custom OneHotEncoder mentioned before. Note that the list contains no neural network algorithms.
The number of combinations appears to be nearly infinite — you can stack algorithms, including instances of the same algorithm. There may be an internal cap on the number of steps in the pipeline, but suffice to say there are a plethora of possible pipelines.
TPOT will likely not result in the same algorithm selection if you run it twice (maybe not even if random_state is set, I found, as discussed below). As the docs explain:
If you’re working with a reasonably complex dataset or run TPOT for a short amount of time, different TPOT runs may result in different pipeline recommendations. TPOT’s optimization algorithm is stochastic in nature, which means that it uses randomness (in part) to search the possible pipeline space. When two TPOT runs recommend different pipelines, this means that the TPOT runs didn’t converge due to lack of time or that multiple pipelines perform more-or-less the same on your dataset.
Less talk — more action. Try out TPOT on some data!