As Connectionist techniques such as Neural Networks are enjoying a wave of popularity, arch-rival Symbolic A.I. is proving to be the right strategic complement for mission critical applications that require dynamic adaptation, verifiability, and explainability.

Photo by Pablo Rebolledo on Unsplash
It seems that wherever there are two categories of some sort, people are very quick to take one side or the other, to then pit both against each other. Artificial Intelligence techniques have traditionally been divided into two categories; Symbolic A.I. and Connectionist A.I. The latter kind have gained significant popularity with recent success stories and media hype, and no one could be blamed for thinking that they are what A.I. is all about. There have even been cases of people spreading false information to diverge attention and funding from more classic A.I. research and development.
The truth of the matter is that each set of techniques has its place. There is no silver bullet A.I. algorithm yet, and trying to use the same algorithm for all problems is just plain stupid. Each has its own strengths and weaknesses, and choosing the right tools for the job is key.
What is Symbolic A.I.?
This category of techniques is sometimes referred to as GOFAI (Good Old Fashioned A.I.) This does not, by any means, imply that the techniques are old or stagnant. It is the more classical approach of encoding a model of the problem and expecting the system to process the input data according to this model to provide a solution.
The need for symbolic techniques is getting a fresh wave of interest of late, with the recognition that for A.I. based systems to be accepted in certain high-risk domains, their behaviour needs to be verifiable and explainable. This is often very difficult to achieve by connectionist algorithms.
The systems that fall into this category often involve deductive reasoning, logical inference, and some flavour of search algorithm that finds a solution within the constraints of the specified model. These include expert systems, which use rules and decision trees to deduce conclusions from the input data, constraint solvers, which search for a solution within a space of possibilities, and planning systems, which try to find a sequence of actions to achieve a well defined goal from some initial state. They often also have variants that are capable of handling uncertainty and risk.
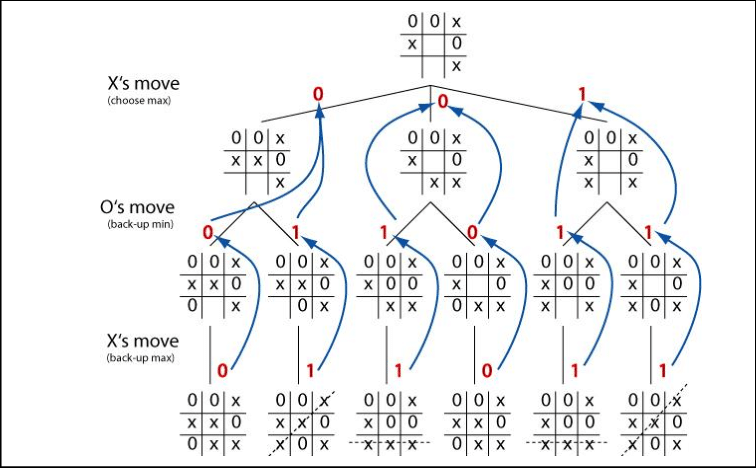
A MiniMax Game Tree for Tic-Tac-Toe. (Image Source)
Such algorithms typically have an algorithmic complexity which is NP-hardor worse, facing super-massive search spaces when trying to solve real-world problems. This means that classical exhaustive blind search algorithms will not work, apart from small artificially restricted cases. Instead, the paths that are least likely to lead to a solution are pruned out of the search space or left unexplored for as long as possible.
There is a plethora of techniques in this category. Branch and boundalgorithms work on optimisation or constraint satisfaction problems where a heuristic is not available, partitioning the solution space by an upper and lower bound, and searching for a solution within that partition. Local searchlooks at close variants of a solution and tries to improve it incrementally, occasionally performing random jumps in an attempt to escape local optima. Meta-heuristics encompass the broader landscape of such techniques, with evolutionary algorithms imitating distributed or collaborative mechanisms found in nature, such as natural selection and swarm-inspired behaviour.
Heuristic search uses an evaluation function to determine the closeness of a state to the goal, using estimates that are cheaper to compute than trying to find the full solution. One noteworthy domain-independent heuristic is relaxation, where the algorithm ignores some of the constraints or possible real-world setbacks to find a faster solution in a more relaxed world. This is used as guidance to make more informed choices at each decision point of the search. A good heuristic which is both admissible (never overestimates the cost) and informative can lead to algorithms such as A* to find optimal solutions, but unfortunately such heuristics are often not available easily. For complex problems, finding a feasible solution that satisfies all constraints, albeit not optimal, is already a big feat.

A* Heuristic Search for finding Shortest Path (Image Source: Wikipedia)
While some techniques can also handle partial observability and probabilistic models, they are typically not appropriate for noisy input data, or scenarios where the model is not well defined. They are more effective in scenarios where it is well-established that taking specific actions in certain situations could be beneficial or disastrous, and the system needs to provide the right mechanism to explictly encode and enforce such rules.
Symbolic algorithms eliminate options that violate the specified model, and can be verified to always produce a solution that satisfies all the constraints much more easily than their connectionist counterparts. Since typically there is barely or no algorithmic training involved, the model can be dynamic, and change as rapidly as needed.
What is Connectionist A.I.?
Connectionist A.I. gets its name from the typical network topology that most of the algorithms in this class employ. The most popular technique in this category is the Artificial Neural Network (ANN). This consists of multiple layers of nodes, called neurons, that process some input signals, combine them together with some weight coefficients, and squash them to be fed to the next layer. Support Vector Machines (SVMs) also fall under the Connectionist category.
ANNs come in various shapes and sizes, including Convolution Neural Networks (successful for image recognition and bitmap classification), and Long Short-term Memory Networks (typically applied for time series analysis or problems where time is an important feature). Deep learning is also essentially synonymous with Artificial Neural Networks.
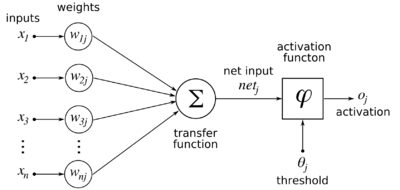
A neuron of an Artificial Neural Network. (Image source: Wikipedia)
The key aspect of this category of techniques is that the user does not specify the rules of the domain being modelled. The network discovers the rules from training data. The user provides input data and sample output data (the larger and more diverse the data set, the better). Connectionist algorithms then apply statistical regression models to adjust the weight coefficients of their intermediate variables, until the best fitting model is found. The weights are adjusted in the direction that minimises the cumulative error from all the training data points, using techniques such as gradient descent.
Since these techniques are effectively error minimisation algorithms, they are inherently resilient to noise. They will smoothen out outliers and converge to a solution that classifies the data within some margin of error.
These algorithms do not need a model of the world. They just need enough sample data from which the model of the world can be inferred statistically. This is a very powerful characteristic, but also a weakness. The input features have to be very carefully selected. They also have to be normalised or scaled, to avoid that one feature overpowers the others, and pre-processed to be more meaningful for classification.
Feature engineering is an occult craft in its own right, and can often be the key determining success factor of a machine learning project. Having too many features, or not having a representative data set that covers most of the permutations of those features, can lead to overfitting or underfitting. Even with the help of the most skilled data scientist, you are still at the mercy of the quality of the data you have available. These techniques are not immune to the curse of dimensionality either, and as the number of input features increases, the higher the risk of an invalid solution.

A Data Scientist sifting for Features — Photo by Artem Maltsev on Unsplash
Data driven algorithms implicitly assume that the model of the world they are capturing is relatively stable. This makes them very effective for problems where the rules of the game are not changing significantly, or changing at a rate that is slow enough to allow sufficient new data samples to be collected for retraining and adaptation to the new reality. Image recognition is the textbook success story, because hot dogs will most likely still look the same a year from now.
Photo by HBO / Twitter.com/TechatBloomberg
So what should you choose?
Choosing the right algorithm is very dependent on the problem you are trying to solve. It is becoming very commonplace that a technique is chosen for the wrong reasons, often due to hype surrounding that technique, or the lack of awareness of the broader landscape of A.I. algorithms. When the tool you have is a hammer, everything starts to look like a nail.
As A.I. proliferates into every aspect of our lives, and requirements become more sophisticated, it is also highly probable that an application will need more than one of these techniques. Noisy data that is gathered through sensors might be processed through an ANN to infer the discrete information about the environment, while a symbolic algorithm uses that information to search the space of possible actions that can lead to some goal at a more abstract logical level.
A machine learning algorithm could be very effective at inferring the surroundings of an autonomous vehicle within a certain level of probability, but that chance of error is not acceptable if it could make it drive off a cliff, just because that scenario was never captured properly in the sample training data. Furthermore, bringing deep learning to mission critical applications is proving to be challenging, especially when a motor scooter gets confused for a parachute just because it was toppled over.
Overlaying a symbolic constraint system ensures that what is logically obvious is still enforced, even if the underlying deep learning layer says otherwise due to some statistical bias or noisy sensor readings. This is becoming increasingly important for high risk applications, like managing power stations, dispatching trains, autopilot systems, and space applications. The implications of misclassification in such systems are much more serious than recommending the wrong movie.
A hybrid system that makes use of both connectionist and symbolic algorithms will capitalise on the strengths of both while counteracting the weaknesses of each other. The limits of using one technique in isolation are already being identified, and latest research has started to show that combining both approaches can lead to a more intelligent solution.
originally published on Medium