Ready to learn Machine Learning? Browse Machine Learning Training and Certification courses developed by industry thought leaders and Experfy in Harvard Innovation Lab.
When someone asks you to guess a person’s age, your mind starts to answer all sorts of questions regarding the person’s demographics, then finally you take a guess. Without even being asked, the human mind inter-relates different abstract concepts that add up together to answer a specific question. That is the essence of learning, and in Machine Learning, we call this a Multi-Task Learning Problem.
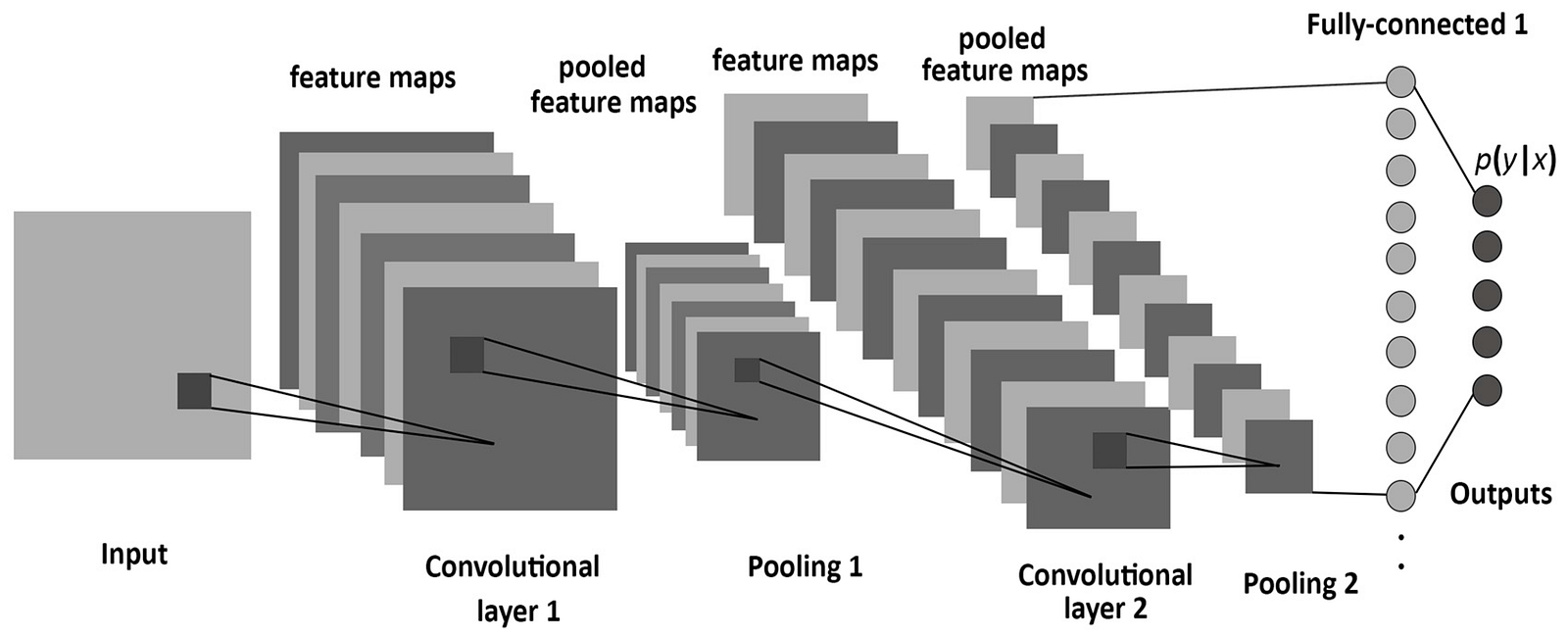
In Multi-Task Learning, we train our machine to answer multiple questions simultaneously, and in the process, features useful for multiple tasks are shared in our model. In a typical Convolutional Neural Network (CNN), an image is passed through a series of convolutions, nonlinearities, and pooling layers. This gives us abstract representations of our image, called feature maps. The feature maps are then optionally fed into a fully connected layer, then a linear classifier to tell which class the image is in. For multi-task learning, the CNN is required to learn a feature map that is useful to solving all the given tasks. This makes multi-task learning models more generalizable and you wouldn’t need to train many similar models, which is wasteful, because the parameters are shared in one network.
In a recent project, I’ve used multi-task learning to train a model to tell a person’s age, gender, and ethnicity. I’d like to share the important components that made this system work.
Datasets & Benchmarks
The dataset I used was UTK Face Dataset. Before trying to build any model, it was important to have a baseline/benchmark performance. I could have trained the model separately for each of age, gender, and ethnicity, and used that as my benchmarks. But I was googling around, and found this nice blog post where the author uses a pretrained model to achieve 94.5% on gender classification and 86.4% on ethnicity classification. That is great, let’s keep those numbers in mind and get on with training our multi-task learning model.
Data Preprocessing
A crucial step in making this system work is to crop and align the faces from the data. A popular way to do this is to use a Histogram of Oriented Gradients(HOG), but I decided to use Multi-Task Cascaded Convolutional Network(MTCNN), the state-of-the-art deep learning model for face detection and alignment. You could easily find a pretrained model online, loop through the folder containing the images, and crop the faces. Below are some sample cropped photos

Each image label is contained in the filename. As explained in the dataset’s homepage,
The labels of each face image is embedded in the file name, formated like `[age]_[gender]_[race]_[date&time].jpg`
`[age]` is an integer from 0 to 116, indicating the age
`[gender]` is either 0 (male) or 1 (female)
`[race]` is an integer from 0 to 4, denoting White, Black, Asian, Indian, and Others (like Hispanic, Latino, Middle Eastern).
`[date&time]` is in the format of yyyymmddHHMMSSFFF, showing the date and time an image was collected to UTKFace
For this project I used Keras with tensorflow backend. Since our labels are contained in the filename, I created a custom image data generator. The generator accepts a list of filenames as input, parses the names, and yields a numpy array of images as well as three lists of labels: age, gender, and ethnicity.
It is noteworthy that you can model age as a real number and view one head of the model as a regression problem. I’ve tried that and the scale of the mean-squared error differed by orders of magnitude from the categorical crossentropies of gender and ethnicity, so it was hard to add the losses up to optimize the total loss. One thing I tried was giving the losses different weights. The model was very sensitive to the weights, and the weight hyperparameters were hard to tune, so I settled back to viewing age as categories. If you view a person’s age as a probability distribution (you could be age x with probability P(X=x)), then your estimated age is the expected value of your age distribution.
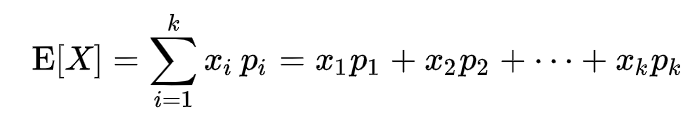
For this, I used softmax to make all the age probabilities add up to 1. Given an image of a face, the model outputs 117 probabilities for age, for which dot product with an array [0,1,2,3,…116] to find the expected age.
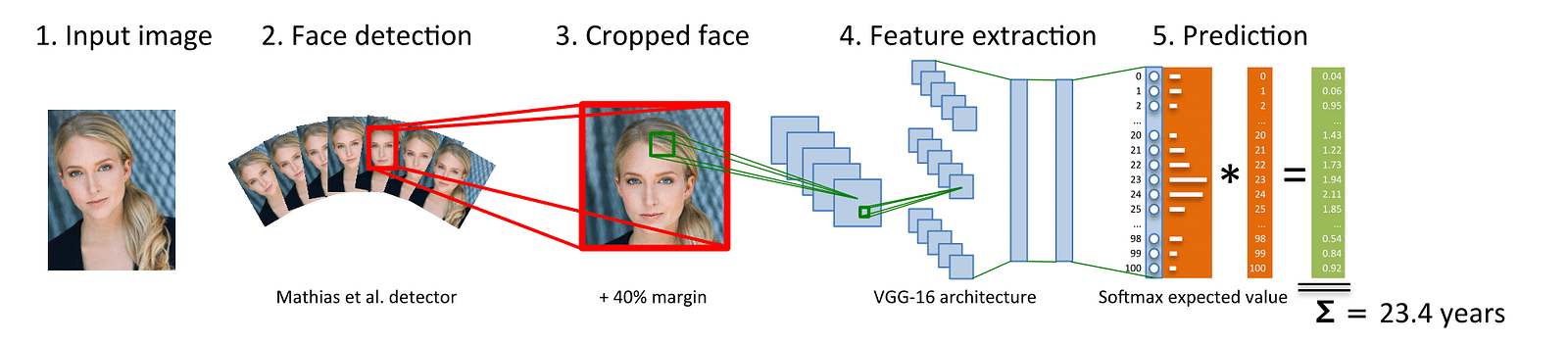
Source: https://data.vision.ee.ethz.ch/cvl/rrothe/imdb-wiki/
The Model
Since the UTK Face dataset is only some 20,000 images big, it is necessary to have a pretrained model for embedding faces. For this, I used FaceNet pretrained on MS-Celeb-1M. You can download the model here. I removed the last 3 layers from the pretrained model (bottle neck layer, batch normalization layer, and dropout layer) because it performed better than having them. Next, I added 2 Fully Connected layers with LeakyReLU as the activation as it seems to perform a little better than the regular ReLU. Finally, I added 3 branches of MLPs after for the outputs. In the figure below, AvgPool: GlobalAveragePooling2D was the final layer from the FaceNet after removing the aforementioned 3 layers.
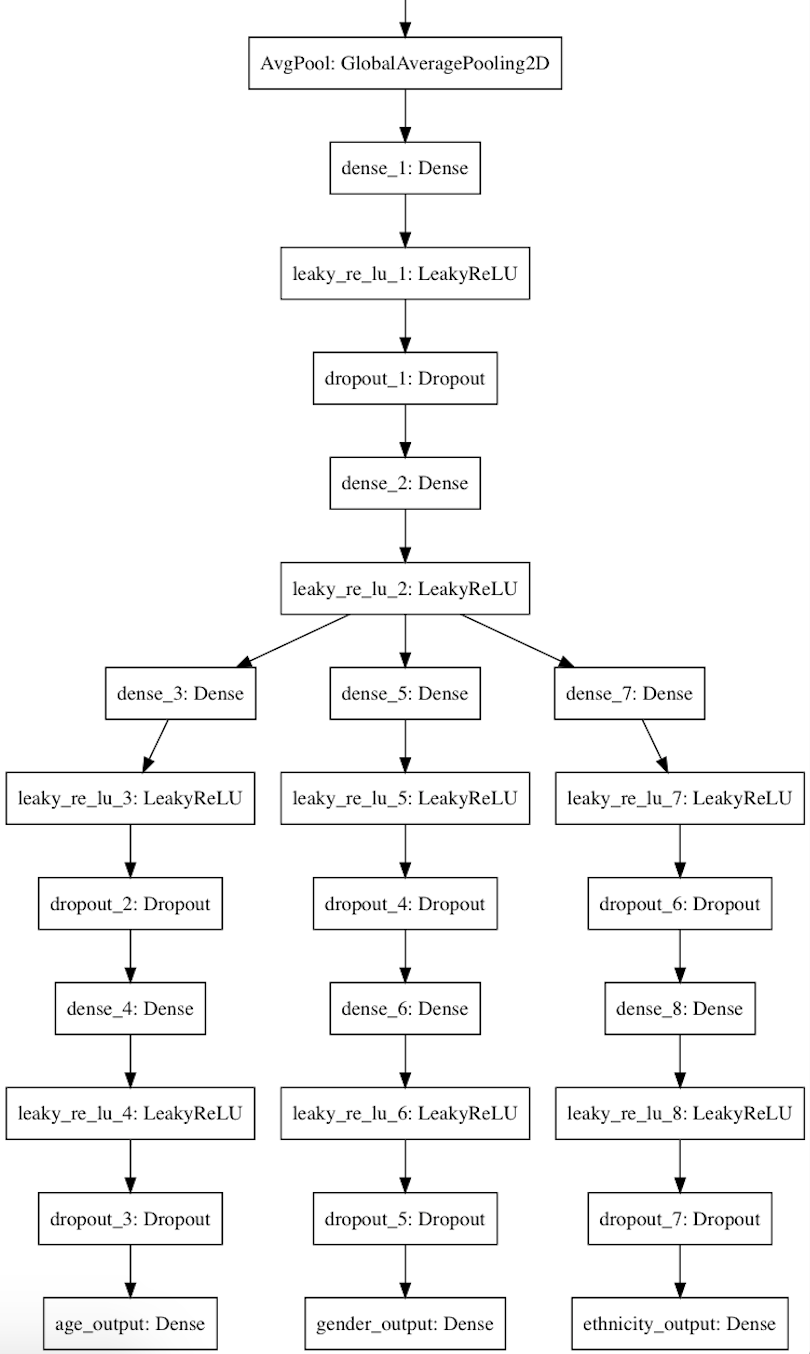
As discussed, all the output layers used softmax as activation, and all were given equal contribution to the final loss. When tested on a test set of 2100 images, the model achieves an Age RMSE of 6.846, Genders Accuracy of 94.84%, and Ethnicities Accuracy of 87.97%.
Here are some predictions from the model:

Whoops, it even got a pretty accurate result of Jeff Bezos, even with his sunglasses on! Another thing to consider when putting this model on production is how big the model was. After some experimenting with the hyperparameters, I was able to reduce the model size from 478 MB to 182 MB while still getting Age RMSE: 7.08, Genders Accuracy: 94.44%, and Ethnicities Accuracy: 86.46%, a very comparable result…! Despite the size differences, both models take around 0.08 seconds on an i7 CPU to predict an image. Imagine how painful it would be if you needed 3 separate models to do each prediction…
Summary
In this post, we walked through the important steps in building a multi-task learning model. As you may already see, most of the models used were pretrained on a bigger dataset. In the world of Deep Learning, you should almost always be using pretrained models of some sort (e.g. ImageNet) as these models are trained on a much bigger dataset that is probably impractical for you to train it on a personal computer. Further, it helps the model converge much faster, and the generalizability is great. Throughout the project, careful considerations of the architecture, hyperparameters, and loss function were extremely important. In the end, hard work paid off, and we got an awesome model!