Ready to learn Artificial Intelligence? Browse courses like Uncertain Knowledge and Reasoning in Artificial Intelligence developed by industry thought leaders and Experfy in Harvard Innovation Lab.
hope this article will provide enough of a technical intuition about the causes of biases in algorithms, while offering an accessible take on how we are inadvertently amplifying existing social and cognitive biases through machine learning — and what we can do to stop it.
What we mean by Bias
When we talk about bias we mean the same thing whatever our discipline. Whether we are talking about cognitive bias, social bias, statistical bias or any other sort of bias, bias is an inaccuracy which is systematically incorrect in the same direction. As a quick example, consider a recruiter who is consistently underestimating the ability of women. The recruiter is not just being unfair, they are actually hurting their own success at hiring good candidates. If it were an algorithm, it would be reducing its accuracy at test time. Bias is not just an ethical issue; it is primarily affecting the success of the person or algorithm which contains it.
On the bright side, because biases are consistently in the same direction, they are quick to fix, which immediately improves both accuracy and fairness. This is true in machine learning algorithms, just as you may try to account for cognitive biases in your brain. Bias is simply an inaccuracy which, once noticed, can be easily, and unquestionably should be, removed.
Biased Data
The fact that statistical biases exist in many ML models, in the same way as cognitive biases exist in people, is little surprise given they are a product of biased data, just as we are a product of our environment and what data we choose to take in. There is a common misconception that a bigger dataset is always better. This belief has held because you can usually increase the accuracy by adding more data. But unfortunately, this increased accuracy won’t translate to in-production accuracy if the additional data is biased and not reflective of the real world. “Garbage in, garbage out” as they say.
Many algorithms which are trained to do a human job, such as recruitment, credit scoring, assigning a prison sentence or diagnosing a patient, will have been trained on human generated data, from past occurrences of a person doing the job. If they are trained on data which contains human bias then of course the algorithms will learn it, but furthermore they are likely to amplify it. This is a huge problem, especially if people assume that algorithms are impartial and can’t hold the same biases as people do.
Biased algorithms have already made it into production
What feels like an arms race around AI recently has created huge pressure for researchers to publish quickly and companies to hastily release their product to the market before someone else does. This has meant there has been little time to step back and actually analyse the biases. That, along with the focus on purely past dataset accuracy, has meant that biased algorithms have been scaled up to production. Here are two quite famous examples; of course bias isn’t just about race and gender, those are just some of the easiest places to notice obvious errors and injustices.
Word2Vec Word Embeddings
Word embeddings were designed to encode the meaning of words in a vector space (if you’re not familiar with vector spaces, just think of a 3D space). This means that words which have a similar meaning are located close together in that space. A nice introduction to word embeddings can be found here if you are interested to know more.
Of course, the “meaning” of a word is very context-dependent and word vectors will learn the word in the context of the training data. By choosing a dataset, you are implicitly making the assumption that the meaning you want is the meaning that you would learn by reading the dataset. For example, it may be useful to have word vectors which understand the medical meaning of words, rather than the colloquial meaning. The word2vec embeddings were trained by Google on the Google News dataset of 100 billion words — or around 125 million news articles. To expect that news articles would not exhibit any bias seems perhaps a little naive.
The difference between two word embeddings also has a meaning, as shown in the example below. “Man is to King as Woman is to …” — the model predicts “Queen”. Below are screenshots from an interactive word embedding combinator. You can try this out for yourself here.
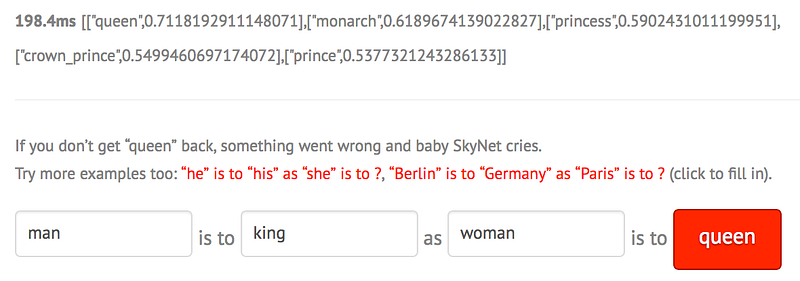
Ok, that’s cool, it seems like the algorithm has some understanding of a feminine vector. However, if we take a look at another example we see the vectors exhibiting gender biasing in lots of jobs — the most noticeably bizarre is the following: “Man is to Computer Programmer as Woman is to …” — “Homemaker”!

Again, this isn’t only an ethical issue, it is also literally just an inaccuracy, a female computer programmer is not a homemaker. This bias, as far as I’m aware, was first noted by a paper published a year ago at NIPS 2016. In this paper, they also explain a method to model and remove this bias.
This bias in word embeddings is actually a huge problem because they are used in a lot of Google products (such as Search and Translate), as well as by a large number of other tech companies. The paper gives the example of how the embeddings are used to improve your search results, meaning that if you are to put “cmu computer science phd student” as a query, then you will be more likely directed to pages of male students because the embedding for male names is closer to the “computer science” embedding.
Another noticeable issue is with Google Translate, which of course uses these word embeddings. If you translate “He is a nurse. She is a doctor.” to Hungarian and then back again you see that the genders are switched around. (try it for yourself; other languages also works, try Turkish).
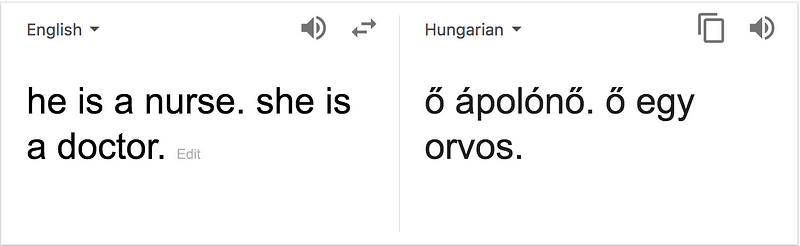
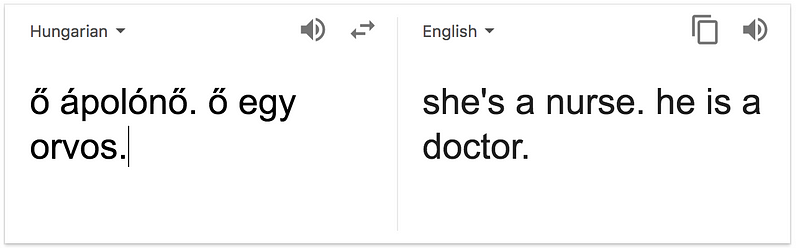
This is just another illustration that the vectors are biased. The future problems arise when these word embeddings are used to generate more texts, for example kids books, exam questions or news articles themselves.
COMPAS
A perhaps more worrying example of bias in production is the Correctional Offender Management Profiling for Alternative Sanctions (COMPAS) algorithm, which was being used by courts in the US to decide on prison sentences. ProPublica independently investigated the algorithm and found it to be biased against black people. They found it was twice as likely to inaccurately predict that a black person would reoffend; and twice as likely to inaccurately predict that a white person would not reoffend. This meant that people were getting higher prison sentences purely based on racial bias. Full details of the study and analysis are in the ProPublica article. The creators of COMPAS did not release details about the algorithm, though there is some indication of the methodology here.
How Discriminative Models amplify bias
Discriminative models (in contrast to Generative Models) are the main cause of bias amplification and are also far more common in production. In a different post I will discuss the merits of Generative Models. In a nutshell, Generative Models learn a specific model of the problem and how each element of it interact with each other, allowing for greater interpretability of the model. Discriminative models, on the other hand, are more “black box” and learn to answer just specific questions.
Discriminative Models
Discriminative models, such as neural networks, logistic regression, SVMs and conditional random fields, have become very popular due to their speed and relative ease of use. You simply put in lots of labelled data (examples of the thing you want to predict or classify) and the model learns to predict the label of future examples, through a combination of generalisations about the training data. No explicit model assumptions are made, your only implicit model assumptions are that the data you are feeding in is unbiased and that the thing you care about most is the accuracy of your predictions.
If doing a classification task they are likely to be trained to maximise classification accuracy. This means that the model will take advantage of whatever information will improve accuracy on the dataset, especially any biases which exist in the data.
Bias Amplification
These models maximise this accuracy by combining many rough generalisations on the data they have been trained on, which is crucially where the amplification of bias comes in. This fact that generalisations amplify bias isn’t immediately intuitive so let me give an example.
Imagine there is an algorithm which aims to predict from an image of a person whether they are a man or a woman. Let’s say it’s 75% accurate. Assume we have a biased dataset which is not reflective of true society (perhaps because, for example, it’s made of images from Hollywood movies). In this dataset, 80% of the time somebody is in the kitchen, it is a woman. The algorithm can then increase its accuracy from 75% to 80% by simply predicting that everyone who is ever in a kitchen is a woman. Since the algorithm simply optimises for accuracy, this is what it will most likely do. So the bias here has been amplified from 80% in the dataset, to 100% in the algorithm.
The less accurate the algorithm is, the more it will take advantage of biases in the data to help improve predictions. In real models the bias is unlikely to be amplified to 100%, but even the use of this bias in the dataset will cause some amplification.
This phenomenon was highlighted in a paper, called “Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints”, which won the Best Paper award at EMNLP this summer. The paper looks at gender bias in datasets and also the image classification and Visual Semantic Role Labelling algorithms which were trained on them. It found that in the imSitu dataset of the images of somebody cooking, they were 66% of the time female. However, once the algorithm was trained, it amplified that bias to predict 84% of the people cooking to be female. The algorithm which was being used here was a conditional random field, a discriminative graphical model. They then proposed a solution to reduce this bias amplification to predict 80% female, without having any negative impact on the accuracy. Furthermore, assuming the bias in the dataset is not reflective of real life, then this algorithm’s real life accuracy will certainly be improved by this step.
So what can we do about it?
Firstly, we Researchers and Data Scientists should be comfortable with the fact that many datasets are not perfectly unbiased, and that optimising our algorithms to fit a dataset perfectly may not be what we need. There may be logical ways to reduce the bias in the dataset, but if not then, as mentioned in this article already, there are many ways to combat this bias technically in the algorithm. There is not one solution for every model, but there will be many methods to remove or at least reduce bias amplification. One solution that I am particularly interested in is to, where possible, use Generative (instead of Discriminative) models. They cannot be used on every problem, but they have the advantage of not amplifying bias in the same way as described earlier. They also increase the interpretability of the model — making it is easy to debug any bias in your dataset.
We should see AI as an opportunity, not an inhibitor to social equality. It is easier to remove biases from algorithms than from people, and so ultimately AI has the potential to create a future where important decisions, such as hiring, diagnoses, and legal judgments, are made in a more fair way.
Although there are indeed technical solutions to reduce bias, finding and implementing them does take some effort. Therefore as a society, we must find ways to keep a check on the bias and incentivise companies to make sure their algorithms are not biased. This could be done by externally testing the algorithm for bias, much like ProPublica did for COMPAS, or could be by asking for greater transparency on the datasets and what the algorithms are optimising for. Otherwise, until AI companies and VC’s realise that past dataset accuracy is not the best metric for real world accuracy, people will keep taking the easy route.