Update: IBM Data Science Experience is now IBM Watson Studio. This post is an excerpt from our solution tutorial that walks you through the process of building a predictive machine learning model, deploying it as an API to be used in applications, testing the model and retraining the model with feedback data. All of this happening in an integrated and unified self-service experience on IBM Cloud.
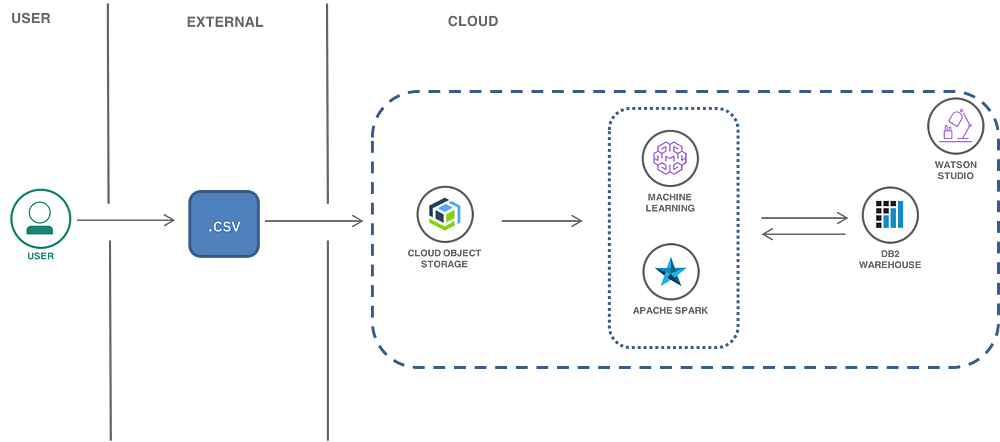
In this post, the famous Iris flower data set is used for creating a machine learning model to classify species of flowers.
In the terminology of machine learning, classification is considered an instance of supervised learning, i.e. learning where a training set of correctly identified observations is available.
Import data to a project
A project is how you organize your resources to achieve a particular goal within Watson Data Platform. Your project resources can include data, collaborators, and analytic tools like Jupyter notebooks and machine learning models.
You can create a project to add data and open a data asset in the data refiner for cleansing and shaping your data.
Create a project:
- Go to the IBM® Cloud catalog and select Watson Studio under the Watson section. Create the service. Click on the Get Started button to launch the Watson Studio dashboard.
2. Create a New Project > Select Complete. Click OK. Add a name say iris_project and optional description for the project.
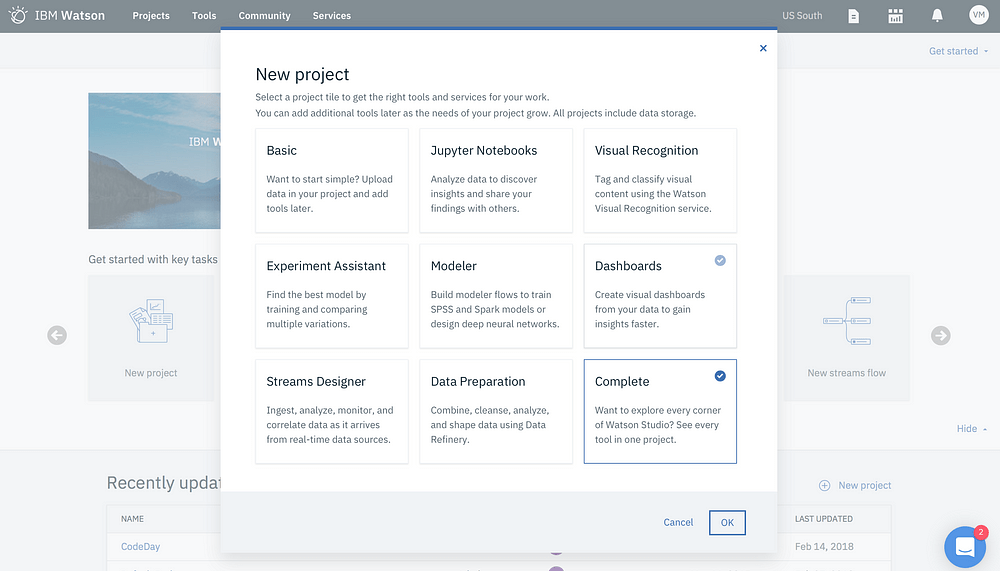
3. Leave the Restrict who can be a collaborator checkbox unchecked as there’s no confidential data.
4. Under Define Storage, Click on Add and choose an existing object storage service or create a new one (Select Lite plan > Create). Hit Refresh to see the created service.
5. Click Create. Your new project opens and you can start adding resources to it.
Import data:
As mentioned earlier, you will be using the Iris data set. The Iris dataset was used in R.A. Fisher’s classic 1936 paper, The Use of Multiple Measurements in Taxonomic Problems, and can also be found on the UCI Machine Learning Repository. This small dataset is often used for testing out machine learning algorithms and visualizations. The aim is to classify Iris flowers among three species (Setosa, Versicolor or Virginica) from measurements of length and width of sepals and petals. The iris data set contains 3 classes of 50 instances each, where each class refers to a type of iris plant.
Download iris_initial.csv which consists of 40 instances of each class. You will use the rest 10 instances of each class to re-train your model.
- Under Assets in your project, click the Find and Add Data icon

2. Under Load, click on browse and upload the downloaded iris_initial.csv.
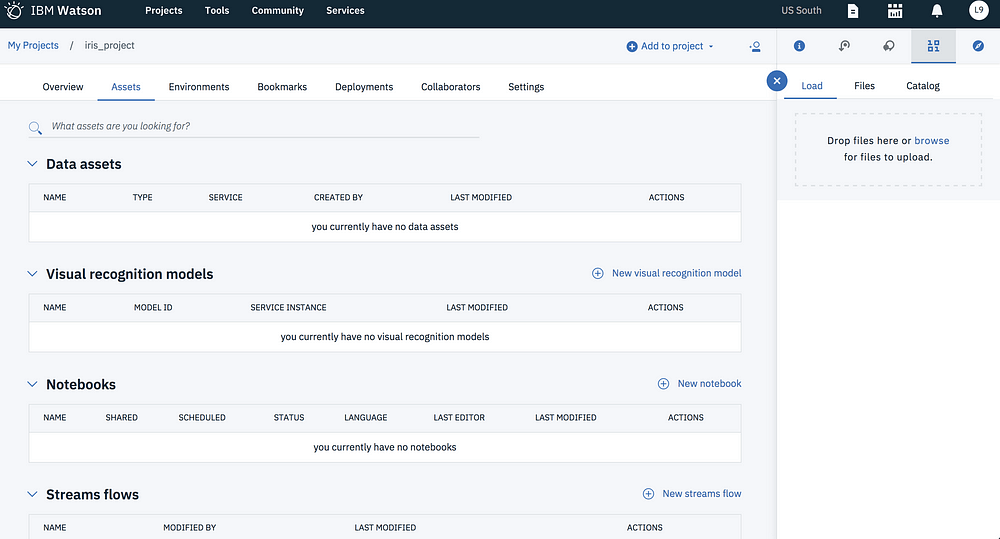
3. Once added, you should see iris_initial.csv in the Data assets section of the project. Click on the name to see the contents of the data set.
Build a machine learning model
- Back in the Assets overview, under Models click on New model. In the dialog, add iris-model as name and an optional description.
- Under Machine Learning Service section, click on Associate a Machine Learning service instance to bind a machine learning service (Lite plan) to your project. Click Reload.
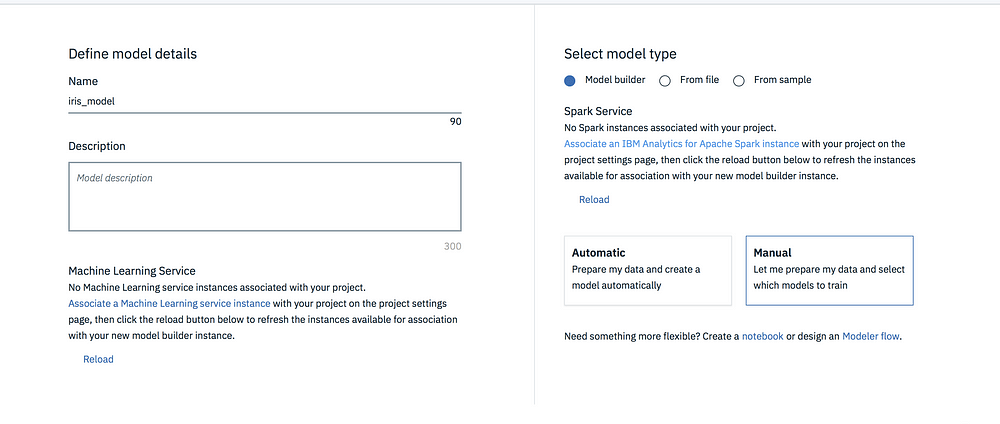
3.Under Spark Service section, click on Associate an IBM Analytics for Apache Spark instance to bind a Apache Spark service (Lite plan) to your project. Click Reload.
4. Select Model builder as your model type and Manual to manually create a model. Click Create.
For the automatic method, you rely on automatic data preparation (ADP) completely. For the manual method, in addition to some functions that are handled by the ADP transformer, you can add and configure your own estimators, which are the algorithms used in the analysis.
5. On the next page, select iris_initial.csv as your data set and click Next.
6. On the Select a technique page, based on the data set added, Label columns and feature columns are pre-populated. Select species (String) as your Label Col and petal_length (Decimal) and petal_width (Decimal) as your Feature columns.
7. Choose Multiclass Classification as your suggested technique.
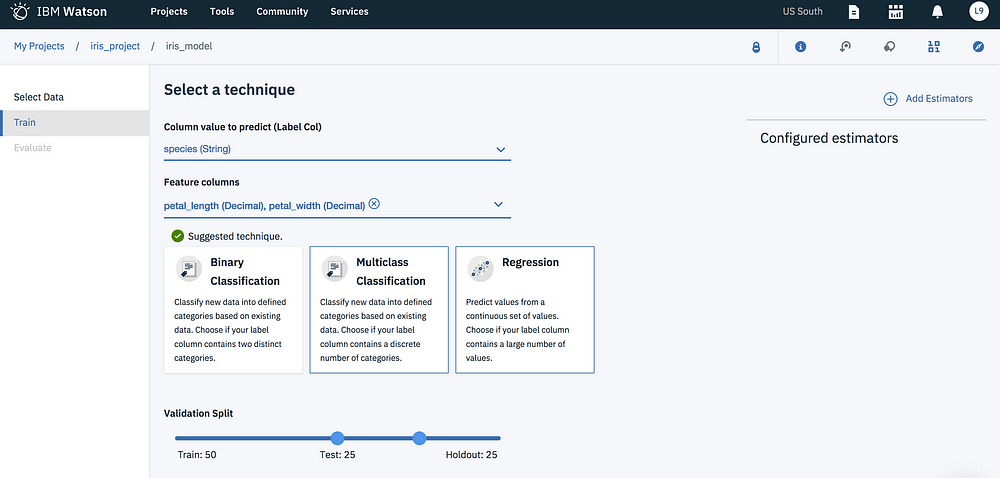
8. For Validation Split configure the following setting:
- Train: 50%,
- Test 25%,
- Holdout: 25%
9. Click on Add Estimators and select Decision Tree Classifier, then Add.
You can evaluate multiple estimators in one go. For example, you can add Decision Tree Classifier and Random Forest Classifier as estimators to train your model and choose the best fit based on the evaluation output.
10. Click Next to train the model. Once you see the status as Trained & Evaluated, click Save.

11. Click on Overview to check the details of the model.
Your journey doesn’t halt here.Following the steps below, you will deploy your model as an API, test it and retrain by creating a feedback data connection.
- Deploy the model and try out the API
- Test your model
- Create a feedback data connection
- Re-train your model