Ready to learn Machine Learning? Browse Machine Learning Training and Certification courses developed by industry thought leaders and Experfy in Harvard Innovation Lab.
There is an explosion of interest in data science today. One just needs to insert the tag-line ‘Powered-by-AI’, and anything sells.
But, that's where the problems begin.
Data science sales pitches often promise the moon. Then, clients raise the expectations a notch up and launch their moonshot projects. Ultimately, it’s left to the data scientists to take clients to the moon, or leave them marooned.
An earlier article, ‘4 Ways to fail a Data scientist Job interview’ looked at the key blunders candidates commit in the pursuit of data science. Here, we wade into the fantasy world of expectations from data science projects and find out the top misconceptions held by clients.
Here we’ll talk about the 8 most common myths I’ve seen in machine learning projects, and why they annoy data scientists. If you’re getting into data science, or are already mainstream, these are potential grenades that might be hurled at you. Hence, it would be handy knowing how to handle them.
“All models are wrong, but some are useful.” — George Box

Photo by Andre Hunter on Unsplash
1. “We want an AI model.. build one to solve THIS problem”
80% of the industry problems in analytics can be solved with simple exploratory data analysis. If machine learning can be an overkill for these, lets not even get started on why AI is futile here. Why use the cannon to kill a fly?
Yes, advanced analytics is cool. Every business likes to score by leading the industry with this investment. And which vendor doesn’t want to flaunt an AI project? But, one needs to educate clients and call out right use cases that warrant the heavy artillery from ML armoury. For all others, convince clients by showing business value using the nifty data analysis toolkits.
“By far, the greatest danger of Artificial Intelligence is that people conclude too early that they understand it.” — Eliezer Yudkowsky
2. “Take this data.. and come back with transformational insights”
Often, clients think their responsibility ends with handing over the data. Some even stop with the problem definition, but we’ll see that in point #4! They ask for analysts to take the data and come back with a deck of ground-shattering business insights, that will change the organisation overnight.
Unfortunately, unlike creative writing, one can’t think up actionable business recommendations in isolation. It calls for continuous iteration and productive dialogues with business users on what is pertinent and actionable for them. Plan for quality time with business folks periodically, throughout the project.
“If you do not know how to ask the right question, you discover nothing. — W. Edward Deming”
3. “Build a model, and save time by skipping unnecessary analysis”
Many analysts overlook the importance of data wrangling and exploratory analysis, even before they open their model toolbox. Given this, the clients can’t be faulted when they expect to cut out ‘unnecessary analysis’ from the critical path, and save precious project time.
Data analysis is a mandatory step to machine learning and all other higher forms of analytics. Without getting a feel for the data, discovering outliers or underlying patterns, models do nothing but shoot in the dark. Always earmark time for analysis, and onboard clients by sharing interesting findings.
The alchemists in their search for gold discovered many other things of greater value. — Arthur Schopenhauer
4. “We have last week’s data, can you predict the next 6 months?“
This is a pet peeve of data scientists. Clients cobble together few rows of data in spreadsheets and expect AI to do the magic of crystal ball gazing, deep into the future. At times this get quite weird, when clients confess to not having any data, and then genuinely wonder if machine learning can fill in the gaps.
Data quality and volume is paramount, and “garbage-in-garbage-out” applies all the more to analytics. Useful statistical techniques help handle data issues and extract more when you have less. For instance, impute the missing points, smote to generate data or use simpler models with low volumes. But this calls for toning down client’s expectations on outcomes by defining some bounds.
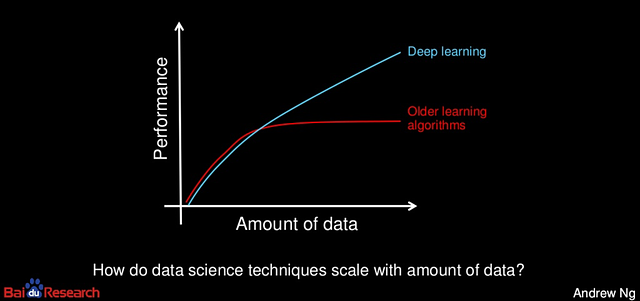
Performance of analytics techniques with data volume: Source Andrew Ng
5. “Can you finish the modelling project in 2 weeks?”
In any business critical project, the results are expected as of yesterday; even when the kickoff is planned today. In a rush to crash project timelines, a common casualty is the model engineering phase. With model APIs and GPU computing at disposal, clients wonder what slows down data scientists.
Inspite of advances in Auto-ML, there is an unmissable manual element in the modelling process. Data scientists must examine statistical results, compare models and check interpretations, often across painful iterations. This cannot be automated away. At least, not yet. Its best to enlighten clients on this quagmire by sharing examples.
Modelling is part-experimentation and part-art, so milestone-driven project plans aren’t always realistic.
6. “Can you replace the Outcome variable and just hit refresh?”
After data scientists crack the problem of modelling business behaviour, new requests crop-up, as final small changes. The ask is often to replace outcome variables, and just re-run the model. Clients miss to realise that such changes don’t merely move goal posts, but switch the game from soccer to basketball.
While machine learning is highly iterative, the core challenge is to pick right influencers for a given outcome variable, and map their relationship. Clients must be educated upfront on how this works, and the levers that they can play with freely. They must also be cautioned on those that need careful planning upfront, and how all hell will break loose if these get changed.
7. “Can we have a model accuracy of 100%?”
People often get hung up on error rates. Quite like a blind pursuit of test grades, clients want the accuracy to be closest to 100%. This turns worrisome when accuracy becomes the singular focus, trumping all other factors. What fun is it to build a highly accurate model that’s too complex to be made live?
The model that won the million dollar Netflix prize with highest accuracy never went live, since its complexity meant heavy engineering costs. Whereas a model with lower accuracy was adopted. Always balance the accuracy with simplicity, stability and business interpretability, by making right trade-offs.
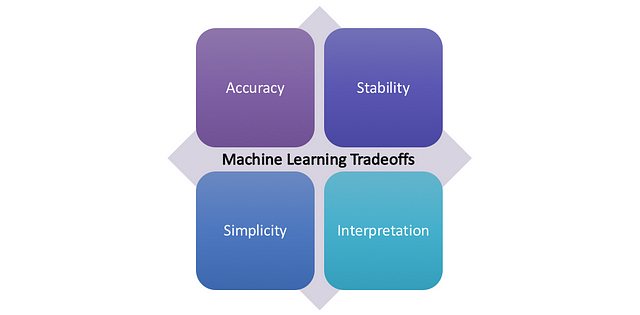
Model Engineering: Achieving the fine balance and trade-off
8. “Can the trained model stay smart forever?”
After putting in the hard work of model building and testing, clients wonder whether the machine has learnt all it ever needs to. A common question is on whether it can stay smart and adapt to future changes in business dynamics?
Unfortunately, machines don’t learn for life. Models need to be constantly and patiently taught. And they need a quick refresher session every few weeks or months, like that struggling student in school. More so, when the context changes. That’s where the analytics industry is today, though its fast evolving. So, for now, do budget time and effort for model maintenance and updates.
Conclusion
We’ve looked at the 8 key misconceptions in projects, which can also be slotted into six phases of the ML modelling lifecycle, as shown below.
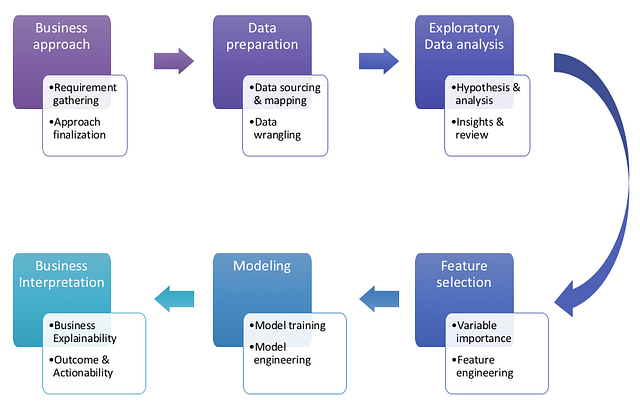
Machine learning project lifecycle
What fuels almost all of the above misconceptions is a lack of awareness and misplaced priorities within a project. Data scientists who understand the reason for these disconnects will be able to educate the stakeholders. And they will be able to address the root causes through gentle prodding and amicable tradeoffs; ones that don’t compromise on the final outcomes.


